如何調用沒有文檔說明的 Web API

大家好!幾天前我寫了篇 小型的個人程序 的文章,裡面提到了調用沒有文檔說明的「秘密」 API 很有意思,你需要從你的瀏覽器中把 cookies 複製出來才能訪問。
有些讀者問如何實現,因此我打算詳細描述下,其實過程很簡單。我們還會談談在調用沒有文檔說明的 API 時,可能會遇到的錯誤和道德問題。
我們用谷歌 Hangouts 舉例。我之所以選擇它,並不是因為這個例子最有用(我認為官方的 API 更實用),而是因為在這個場景中更有用的網站很多是小網站,而小網站的 API 一旦被濫用,受到的傷害會更大。因此我們使用谷歌 Hangouts,因為我 100% 肯定谷歌論壇可以抵禦這種試探行為。
我們現在開始!
第一步:打開開發者工具,找一個 JSON 響應
我瀏覽了 https://hangouts.google.com,在 Firefox 的開發者工具中打開「 網路 」標籤,找到一個 JSON 響應。你也可以使用 Chrome 的開發者工具。
打開之後界面如下圖:
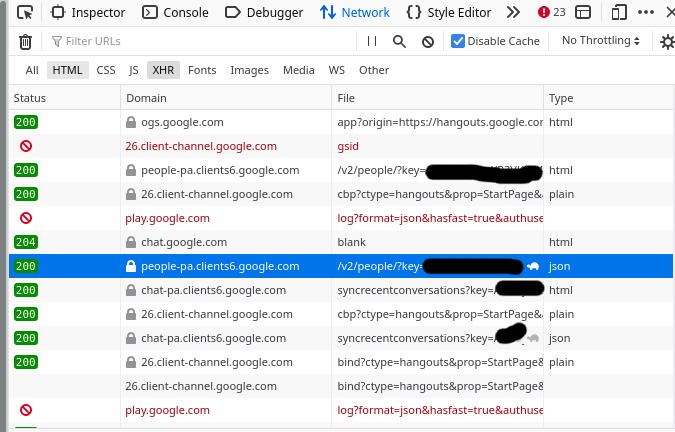
找到其中一條 「 類型 」 列顯示為 json 的請求。
為了找一條感興趣的請求,我找了好一會兒,突然我找到一條 「people」 的端點,看起來是返回我們的聯繫人信息。聽起來很有意思,我們來看一下。
第二步:複製為 cURL
下一步,我在感興趣的請求上右鍵,點擊 「複製Copy」 -> 「 複製為 cURL 」。
然後我把 curl 命令粘貼到終端並運行。下面是運行結果:
$ curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' -X POST ........ (省略了大量請求標頭)
Warning: Binary output can mess up your terminal. Use "--output -" to tell
Warning: curl to output it to your terminal anyway, or consider "--output
Warning: <FILE>" to save to a file.
你可能會想 —— 很奇怪,「二進位的輸出在你的終端上無法正常顯示」 是什麼錯誤?原因是,瀏覽器默認情況下發給伺服器的請求頭中有 Accept-Encoding: gzip, deflate 參數,會把輸出結果進行壓縮。
我們可以通過管道把輸出傳遞給 gunzip 來解壓,但是我們發現不帶這個參數進行請求會更簡單。因此我們去掉一些不相關的請求頭。
第三步:去掉不相關的請求頭
下面是我從瀏覽器獲得的完整 curl 命令。有很多行!我用反斜杠(``)把請求分開,這樣每個請求頭佔一行,看起來更清晰:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED'
-X POST
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0'
-H 'Accept: */*'
-H 'Accept-Language: en'
-H 'Accept-Encoding: gzip, deflate'
-H 'X-HTTP-Method-Override: GET'
-H 'Authorization: SAPISIDHASH REDACTED'
-H 'Cookie: REDACTED'
-H 'Content-Type: application/x-www-form-urlencoded'
-H 'X-Goog-AuthUser: 0'
-H 'Origin: https://hangouts.google.com'
-H 'Connection: keep-alive'
-H 'Referer: https://hangouts.google.com/'
-H 'Sec-Fetch-Dest: empty'
-H 'Sec-Fetch-Mode: cors'
-H 'Sec-Fetch-Site: same-site'
-H 'Sec-GPC: 1'
-H 'DNT: 1'
-H 'Pragma: no-cache'
-H 'Cache-Control: no-cache'
-H 'TE: trailers'
--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'
第一眼看起來內容有很多,但是現在你不需要考慮每一行是什麼意思。你只需要把不相關的行刪掉就可以了。
我通常通過刪掉某行查看是否有錯誤來驗證該行是不是可以刪除 —— 只要請求沒有錯誤就一直刪請求頭。通常情況下,你可以刪掉 Accept*、Referer、Sec-*、DNT、User-Agent 和緩存相關的頭。
在這個例子中,我把請求刪成下面的樣子:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED'
-X POST
-H 'Authorization: SAPISIDHASH REDACTED'
-H 'Content-Type: application/x-www-form-urlencoded'
-H 'Origin: https://hangouts.google.com'
-H 'Cookie: REDACTED'
--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'
這樣我只需要 4 個請求頭:Authorization、Content-Type、Origin 和 Cookie。這樣容易管理得多。
第四步:在 Python 中發請求
現在我們知道了我們需要哪些請求頭,我們可以把 curl 命令翻譯進 Python 程序!這部分是相當機械化的過程,目標僅僅是用 Python 發送與 cUrl 相同的數據。
下面是代碼實例。我們使用 Python 的 requests 包實現了與前面 curl 命令相同的功能。我把整個長請求分解成了元組的數組,以便看起來更簡潔。
import requests
import urllib
data = [
('personId','101777723'), # I redacted these IDs a bit too
('personId','117533904'),
('personId','111526653'),
('personId','116731406'),
('extensionSet.extensionNames','HANGOUTS_ADDITIONAL_DATA'),
('extensionSet.extensionNames','HANGOUTS_OFF_NETWORK_GAIA_GET'),
('extensionSet.extensionNames','HANGOUTS_PHONE_DATA'),
('includedProfileStates','ADMIN_BLOCKED'),
('includedProfileStates','DELETED'),
('includedProfileStates','PRIVATE_PROFILE'),
('mergedPersonSourceOptions.includeAffinity','CHAT_AUTOCOMPLETE'),
('coreIdParams.useRealtimeNotificationExpandedAcls','true'),
('requestMask.includeField.paths','person.email'),
('requestMask.includeField.paths','person.gender'),
('requestMask.includeField.paths','person.in_app_reachability'),
('requestMask.includeField.paths','person.metadata'),
('requestMask.includeField.paths','person.name'),
('requestMask.includeField.paths','person.phone'),
('requestMask.includeField.paths','person.photo'),
('requestMask.includeField.paths','person.read_only_profile_info'),
('requestMask.includeField.paths','person.organization'),
('requestMask.includeField.paths','person.location'),
('requestMask.includeField.paths','person.cover_photo'),
('requestMask.includeContainer','PROFILE'),
('requestMask.includeContainer','DOMAIN_PROFILE'),
('requestMask.includeContainer','CONTACT'),
('key','REDACTED')
]
response = requests.post('https://people-pa.clients6.google.com/v2/people/?key=REDACTED',
headers={
'X-HTTP-Method-Override': 'GET',
'Authorization': 'SAPISIDHASH REDACTED',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://hangouts.google.com',
'Cookie': 'REDACTED',
},
data=urllib.parse.urlencode(data),
)
print(response.text)
我執行這個程序後正常運行 —— 輸出了一堆 JSON 數據!太棒了!
你會注意到有些地方我用 REDACTED 代替了,因為如果我把原始數據列出來你就可以用我的賬號來訪問谷歌論壇了,這就很不好了。
運行結束!
現在我可以隨意修改 Python 程序,比如傳入不同的參數,或解析結果等。
我不打算用它來做其他有意思的事了,因為我壓根對這個 API 沒興趣,我只是用它來闡述請求 API 的過程。
但是你確實可以對返回的一堆 JSON 做一些處理。
curlconverter 看起來很強大
有人評論說可以使用 https://curlconverter.com/ 自動把 curl 轉換成 Python(和一些其他的語言!),這看起來很神奇 —— 我都是手動轉的。我在這個例子里使用了它,看起來一切正常。
追蹤 API 的處理過程並不容易
我不打算誇大追蹤 API 處理過程的難度 —— API 的處理過程並不明顯!我也不知道傳給這個谷歌論壇 API 的一堆參數都是做什麼的!
但是有一些參數看起來很直觀,比如 requestMask.includeField.paths=person.email 可能表示「包含每個人的郵件地址」。因此我只關心我能看懂的參數,不關心看不懂的。
(理論上)適用於所有場景
可能有人質疑 —— 這個方法適用於所有場景嗎?
答案是肯定的 —— 瀏覽器不是魔法!瀏覽器發送給你的伺服器的所有信息都是 HTTP 請求。因此如果我複製了瀏覽器發送的所有的 HTTP 請求頭,那麼後端就會認為請求是從我的瀏覽器發出的,而不是用 Python 程序發出的。
當然,我們去掉了一些瀏覽器發送的請求頭,因此理論上後端是可以識別出來請求是從瀏覽器還是 Python 程序發出的,但是它們通常不會檢查。
這裡有一些對讀者的告誡 —— 一些谷歌服務的後端會通過令人難以理解(對我來說是)方式跟前端通信,因此即使理論上你可以模擬前端的請求,但實際上可能行不通。可能會遭受更多攻擊的大型 API 會有更多的保護措施。
我們已經知道了如何調用沒有文檔說明的 API。現在我們再來聊聊可能遇到的問題。
問題 1:會話 cookie 過期
一個大問題是我用我的谷歌會話 cookie 作為身份認證,因此當我的瀏覽器會話過期後,這個腳本就不能用了。
這意味著這種方式不能長久使用(我寧願調一個真正的 API),但是如果我只是要一次性快速抓取一小組數據,那麼可以使用它。
問題 2:濫用
如果我正在請求一個小網站,那麼我的 Python 腳本可能會把服務打垮,因為請求數超出了它們的處理能力。因此我請求時盡量謹慎,盡量不過快地發送大量請求。
這尤其重要,因為沒有官方 API 的網站往往是些小網站且沒有足夠的資源。
很明顯在這個例子中這不是問題 —— 我認為在寫這篇文章的過程我一共向谷歌論壇的後端發送了 20 次請求,他們肯定可以處理。
如果你用自己的賬號身份過度訪問這個 API 並導致了故障,那麼你的賬號可能會被暫時封禁(情理之中)。
我只下載我自己的數據或公共的數據 —— 我的目的不是尋找網站的弱點。
請記住所有人都可以訪問你沒有文檔說明的 API
我認為本文最重要的信息並不是如何使用其他人沒有文檔說明的 API。雖然很有趣,但是也有一些限制,而且我也不會經常這麼做。
更重要的一點是,任何人都可以這麼訪問你後端的 API!每個人都有開發者工具和網路標籤,查看你傳到後端的參數、修改它們都很容易。
因此如果一個人通過修改某些參數來獲取其他用戶的信息,這不值得提倡。我認為提供公開 API 的大部分開發者們都知道,但是我之所以再提一次,是因為每個初學者都應該了解。: )
via: https://jvns.ca/blog/2022/03/10/how-to-use-undocumented-web-apis/
作者:Julia Evans 選題:lujun9972 譯者:lxbwolf 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









