百度運用 FPGA 方法大規模加速 SQL 查詢

儘管我們對百度今年工作焦點的關注集中在這個中國搜索巨頭在深度學習方面的舉措上,許多其他的關鍵的,儘管不那麼前沿的應用表現出了大數據帶來的挑戰。
正如百度的歐陽劍在本周 Hot Chips 大會上談論的,百度坐擁超過 1 EB 的數據,每天處理大約 100 PB 的數據,每天更新 100 億的網頁,每 24 小時更新處理超過 1 PB 的日誌更新,這些數字和 Google 不分上下,正如人們所想像的。百度採用了類似 Google 的方法去大規模地解決潛在的瓶頸。
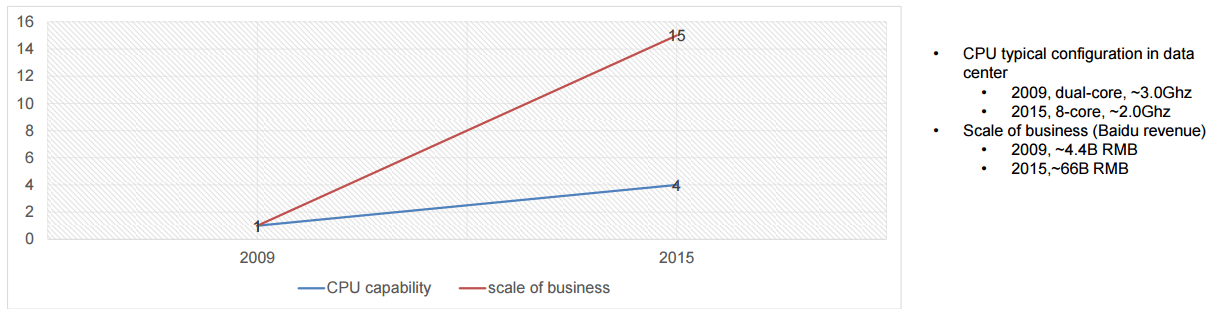
正如剛剛我們談到的,Google 尋找一切可能的方法去打敗摩爾定律,百度也在進行相同的探索,而令人激動的、使人著迷的機器學習工作是迷人的,業務的核心關鍵任務的加速同樣也是,因為必須如此。歐陽提到,公司基於自身的數據提供高端服務的需求和 CPU 可以承載的能力之間的差距將會逐漸增大。
對於百度的百億億級問題,在所有數據的接受端是一系列用於數據分析的框架和平台,從該公司的海量知識圖譜,多媒體工具,自然語言處理框架,推薦引擎,和點擊流分析都是這樣。簡而言之,大數據的首要問題就是這樣的:一系列各種應用和與之匹配的具有壓倒性規模的數據。
當談到加速百度的大數據分析,所面臨的幾個挑戰,歐陽談到抽象化運算核心去尋找一個普適的方法是困難的。「大數據應用的多樣性和變化的計算類型使得這成為一個挑戰,把所有這些整合成為一個分散式系統是困難的,因為有多變的平台和編程模型(MapReduce,Spark,streaming,user defined,等等)。將來還會有更多的數據類型和存儲格式。」
儘管存在這些障礙,歐陽講到他們團隊找到了(它們之間的)共同線索。如他所指出的那樣,那些把他們的許多數據密集型的任務相連繫在一起的就是傳統的 SQL。「我們的數據分析任務大約有 40% 是用 SQL 寫的,而其他的用 SQL 重寫也是可用做到的。」 更進一步,他講道他們可以享受到現有的 SQL 系統的好處,並可以和已有的框架相匹配,比如 Hive,Spark SQL,和 Impala 。下一步要做的事情就是 SQL 查詢加速,百度發現 FPGA 是最好的硬體。

這些主板,被稱為處理單元( 下圖中的 PE ),當執行 SQL 時會自動地處理關鍵的 SQL 功能。這裡所說的都是來自演講,我們不承擔責任。確切的說,這裡提到的 FPGA 有點神秘,或許是故意如此。如果百度在基準測試中得到了如下圖中的提升,那這可是一個有競爭力的信息。後面我們還會繼續介紹這裡所描述的東西。簡單來說,FPGA 運行在資料庫中,當其收到 SQL 查詢的時候,該團隊設計的軟體就會與之緊密結合起來。
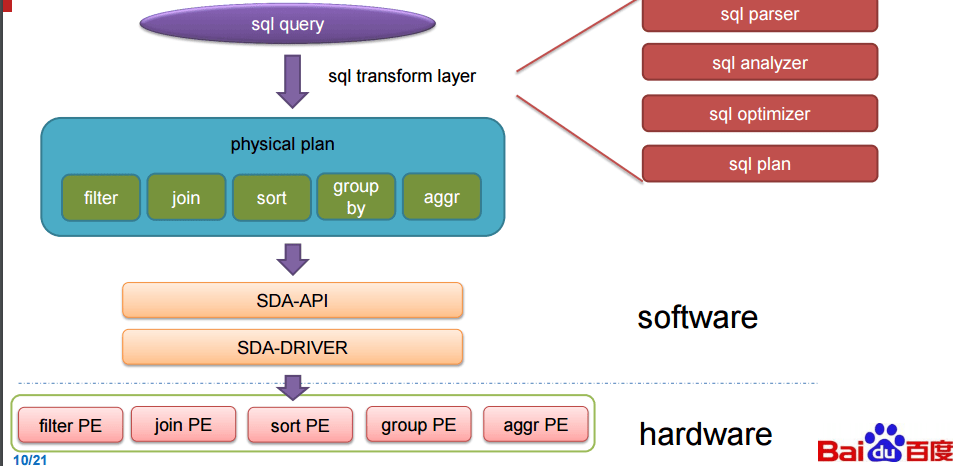
歐陽提到了一件事,他們的加速器受限於 FPGA 的帶寬,不然性能表現本可以更高,在下面的評價中,百度安裝了 2 塊12 核心,主頻 2.0 GHz 的 intl E26230 CPU,運行在 128G 內存。SDA 具有 5 個處理單元,(上圖中的 300MHz FPGA 主板)每個分別處理不同的核心功能( 篩選 , 排序 , 聚合 , 聯合 和 分組 )
為了實現 SQL 查詢加速,百度針對 TPC-DS 的基準測試進行了研究,並且創建了稱做處理單元(PE)的特殊引擎,用於在基準測試中加速 5 個關鍵功能,這包括 篩選 , 排序 , 聚合 , 聯合 和 分組 ,(我們並沒有把這些單詞都像 SQL 那樣大寫)。SDA 設備使用卸載模型,具有多個不同種類的處理單元的加速卡在 FPGA 中組成邏輯,SQL 功能的類型和每張卡的數量由特定的工作量決定。由於這些查詢在百度的系統中執行,用來查詢的數據被以列格式推送到加速卡中(這會使得查詢非常快速),而且通過一個統一的 SDA API 和驅動程序,SQL 查詢工作被分發到正確的處理單元而且 SQL 操作實現了加速。
SDA 架構採用一種數據流模型,加速單元不支持的操作被退回到資料庫系統然後在那裡本地運行,比其他任何因素,百度開發的 SQL 加速卡的性能被 FPGA 卡的內存帶寬所限制。加速卡跨整個集群機器工作,順便提一下,但是數據和 SQL 操作如何分發到多個機器的準確原理沒有被百度披露。
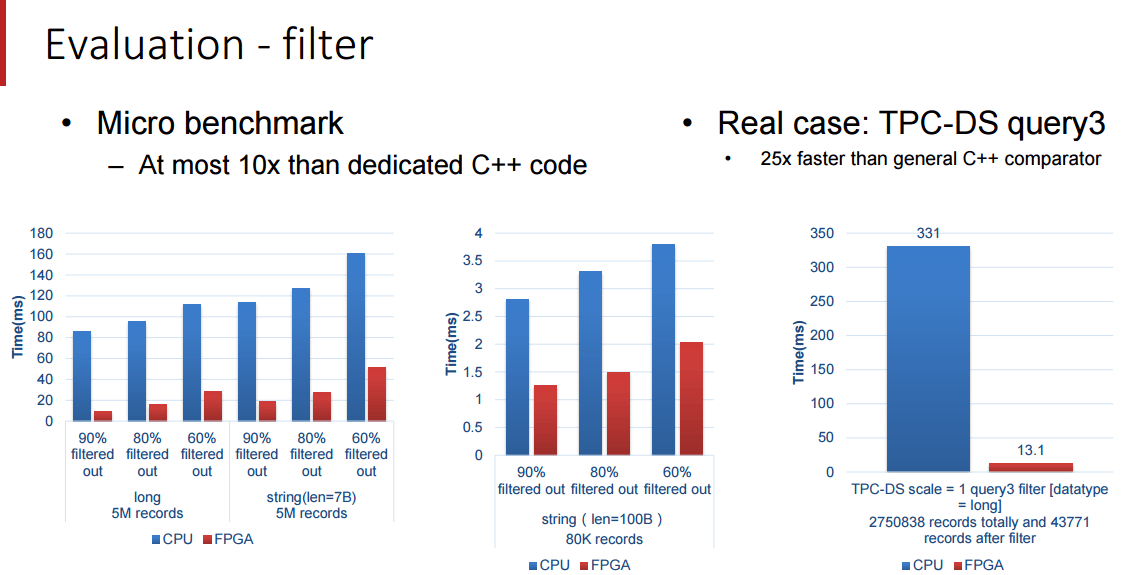
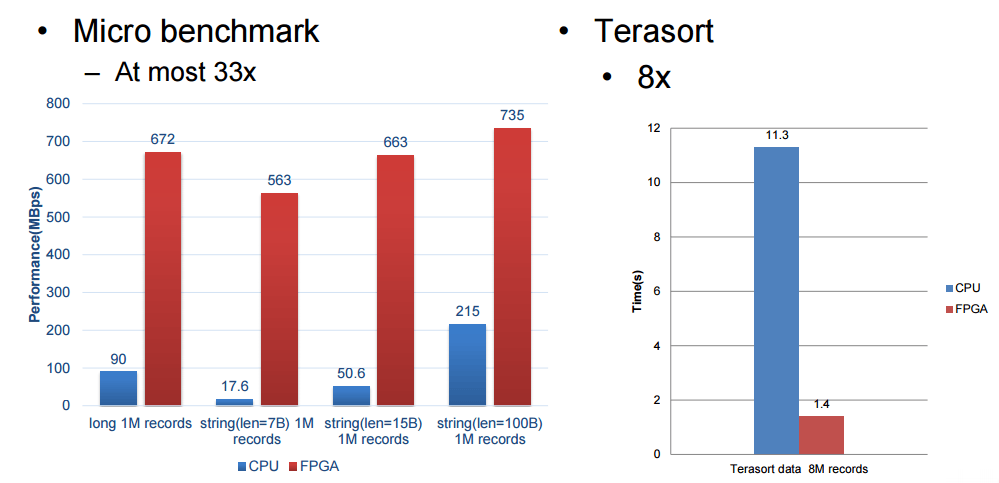
我們受限與百度所願意披露的細節,但是這些基準測試結果是十分令人鼓舞的,尤其是 Terasort 方面,我們將在 Hot Chips 大會之後跟隨百度的腳步去看看我們是否能得到關於這是如何連接到一起的和如何解決內存帶寬瓶頸的細節。
via: http://www.nextplatform.com/2016/08/24/baidu-takes-fpga-approach-accelerating-big-sql/
作者:Nicole Hemsoth 譯者:LinuxBars 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









