awk 系列:如何使用 awk 按模式篩選文本或字元串

作為 awk 命令系列的第三部分,這次我們將看一看如何基於用戶定義的特定模式來篩選文本或字元串。
在篩選文本時,有時你可能想根據某個給定的條件或使用一個可被匹配的特定模式,去標記某個文件或數行字元串中的某幾行。使用 awk 來完成這個任務是非常容易的,這也正是 awk 中可能對你有所幫助的幾個功能之一。
讓我們看一看下面這個例子,比方說你有一個寫有你想要購買的食物的購物清單,其名稱為 food_prices.list,它所含有的食物名稱及相應的價格如下所示:
$ cat food_prices.list
No Item_Name Quantity Price
1 Mangoes 10 $2.45
2 Apples 20 $1.50
3 Bananas 5 $0.90
4 Pineapples 10 $3.46
5 Oranges 10 $0.78
6 Tomatoes 5 $0.55
7 Onions 5 $0.45
然後,你想使用一個 (*) 符號去標記那些單價大於 $2 的食物,那麼你可以通過運行下面的命令來達到此目的:
$ awk '/ *$[2-9].[0-9][0-9] */ { print $1, $2, $3, $4, "*" ; } / *$[0-1].[0-9][0-9] */ { print ; }' food_prices.list
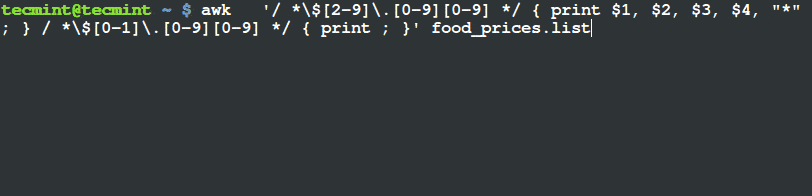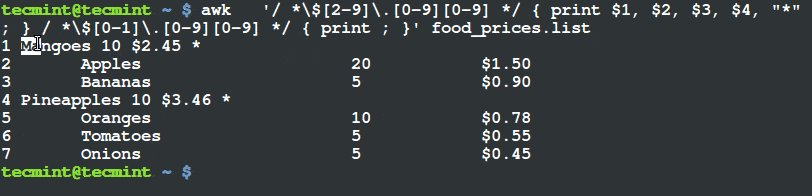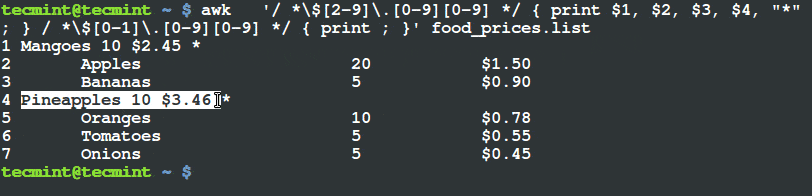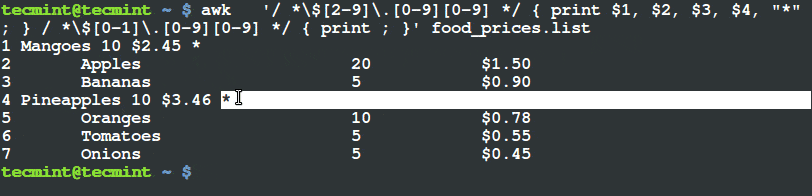
列印出單價大於 $2 的項目
從上面的輸出你可以看到在含有 芒果 和 菠蘿 的那行末尾都已經有了一個 (*) 標記。假如你檢查它們的單價,你可以看到它們的單價的確超過了 $2 。
在這個例子中,我們已經使用了兩個模式:
- 第一個模式:
/ *$[2-9].[0-9][0-9] */將會得到那些含有食物單價大於 $2 的行, - 第二個模式:
/*$[0-1].[0-9][0-9] */將查找那些食物單價小於 $2 的那些行。
上面的命令具體做了什麼呢?這個文件有四個欄位,當模式一匹配到含有食物單價大於 $2 的行時,它便會輸出所有的四個欄位並在該行末尾加上一個 (*) 符號來作為標記。
第二個模式只是簡單地輸出其他含有食物單價小於 $2 的行,按照它們出現在輸入文件 food_prices.list 中的樣子。
這樣你就可以使用模式來篩選出那些價格超過 $2 的食物項目,儘管上面的輸出還有些問題,帶有 (*) 符號的那些行並沒有像其他行那樣被格式化輸出,這使得輸出顯得不夠清晰。
我們在 awk 系列的第二部分中也看到了同樣的問題,但我們可以使用下面的兩種方式來解決:
1、可以像下面這樣使用 printf 命令,但這樣使用又長又無聊:
$ awk '/ *$[2-9].[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10sn", $1, $2, $3, $4 "*" ; } / *$[0-1].[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10sn", $1, $2, $3, $4; }' food_prices.list
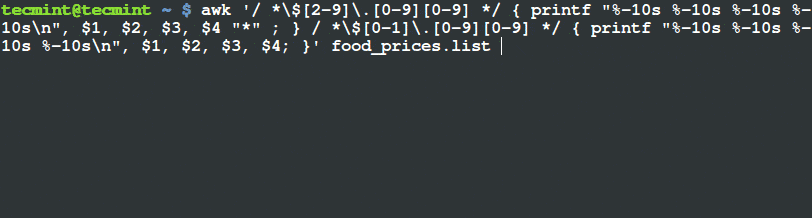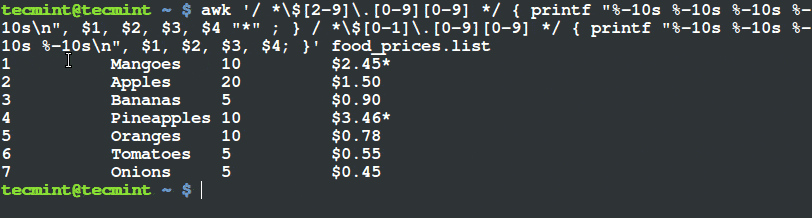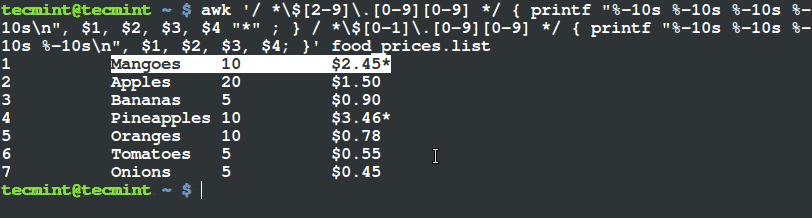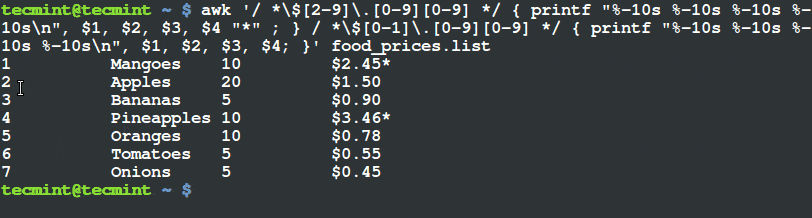
使用 Awk 和 Printf 來篩選和輸出項目
2、 使用 $0 欄位。Awk 使用變數 0 來存儲整個輸入行。對於上面的問題,這種方式非常方便,並且它還簡單、快速:
$ awk '/ *$[2-9].[0-9][0-9] */ { print $0 "*" ; } / *$[0-1].[0-9][0-9] */ { print ; }' food_prices.list
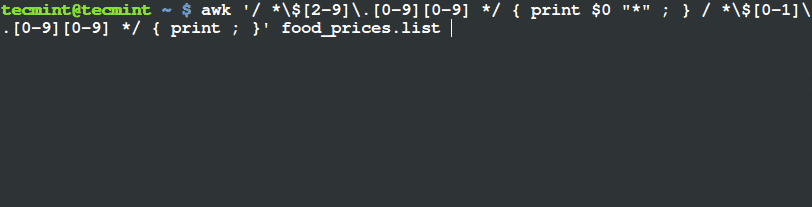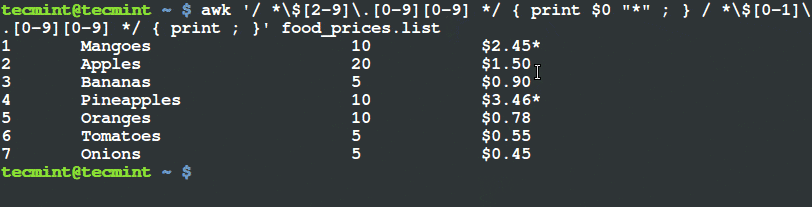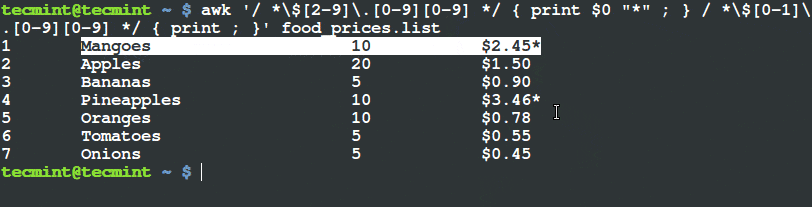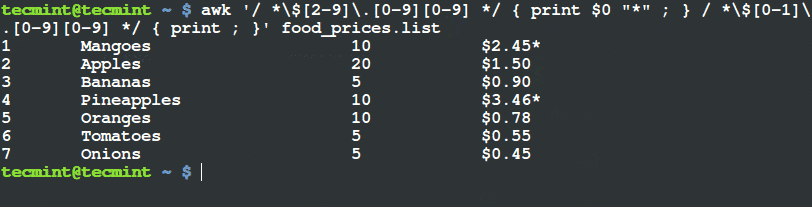
使用 Awk 和變數來篩選和輸出項目
結論
這就是全部內容了,使用 awk 命令你便可以通過幾種簡單的方法去利用模式匹配來篩選文本,幫助你在一個文件中對文本或字元串的某些行做標記。
希望這篇文章對你有所幫助。記得閱讀這個系列的下一部分,我們將關注在 awk 工具中使用比較運算符。
via: http://www.tecmint.com/awk-filter-text-or-string-using-patterns/
作者:Aaron Kili 譯者:FSSlc 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









