awk 系列:如何使用 awk 和正則表達式過濾文本或文件中的字元串

當我們在 Unix/Linux 下使用特定的命令從字元串或文件中讀取或編輯文本時,我們經常需要過濾輸出以得到感興趣的部分。這時正則表達式就派上用場了。
什麼是正則表達式?
正則表達式可以定義為代表若干個字元序列的字元串。它最重要的功能之一就是它允許你過濾一條命令或一個文件的輸出、編輯文本或配置文件的一部分等等。
正則表達式的特點
正則表達式由以下內容組合而成:
- 普通字元,例如空格、下劃線、A-Z、a-z、0-9。
- 可以擴展為普通字元的元字元,它們包括:
(.)它匹配除了換行符外的任何單個字元。(*)它匹配零個或多個在其之前緊挨著的字元。[ character(s) ]它匹配任何由其中的字元/字符集指定的字元,你可以使用連字元(-)代表字元區間,例如 [a-f]、[1-5]等。^它匹配文件中一行的開頭。$它匹配文件中一行的結尾。- `` 這是一個轉義字元。
你必須使用類似 awk 這樣的文本過濾工具來過濾文本。你還可以把 awk 自身當作一個編程語言。但由於這個指南的適用範圍是關於使用 awk 的,我會按照一個簡單的命令行過濾工具來介紹它。
awk 的一般語法如下:
# awk 'script' filename
此處 'script' 是一個由 awk 可以理解並應用於 filename 的命令集合。
它通過讀取文件中的給定行,複製該行的內容並在該行上執行腳本的方式工作。這個過程會在該文件中的所有行上重複。
該腳本 'script' 中內容的格式是 '/pattern/ action',其中 pattern 是一個正則表達式,而 action 是當 awk 在該行中找到此模式時應當執行的動作。
如何在 Linux 中使用 awk 過濾工具
在下面的例子中,我們將聚焦於之前討論過的元字元。
一個使用 awk 的簡單示例:
下面的例子列印文件 /etc/hosts 中的所有行,因為沒有指定任何的模式。
# awk '//{print}' /etc/hosts
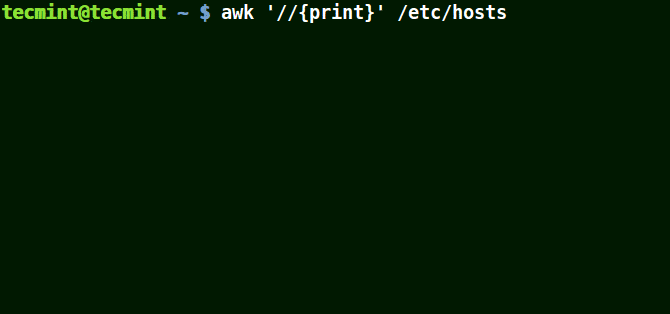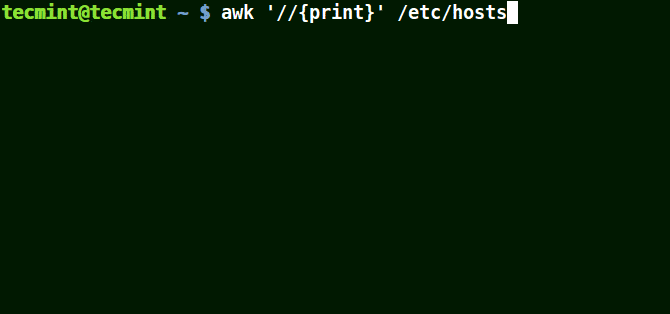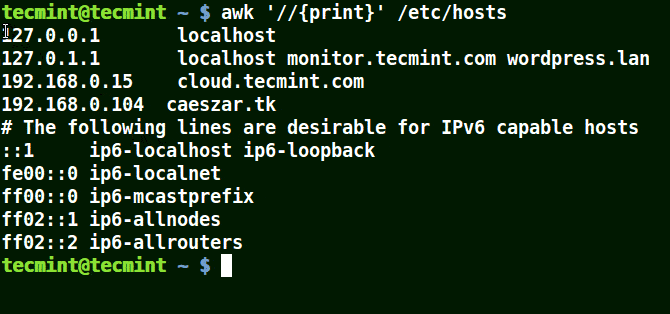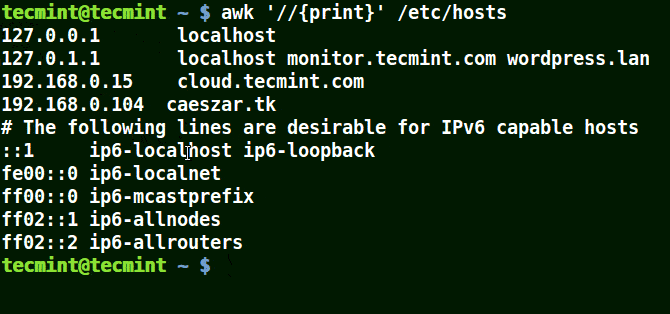
awk 列印文件中的所有行
結合模式使用 awk
在下面的示例中,指定了模式 localhost,因此 awk 將匹配文件 /etc/hosts 中有 localhost 的那些行。
# awk '/localhost/{print}' /etc/hosts

awk 列印文件中匹配模式的行
在 awk 模式中使用通配符 (.)
在下面的例子中,符號 (.) 將匹配包含 loc、localhost、localnet 的字元串。
這裡的正則表達式的意思是匹配 l一個字元c。
# awk '/l.c/{print}' /etc/hosts
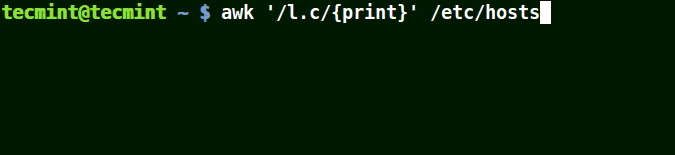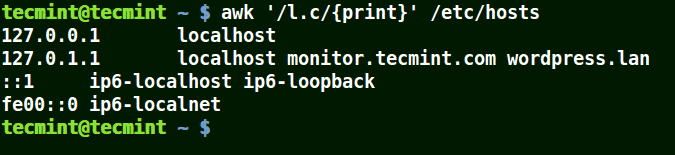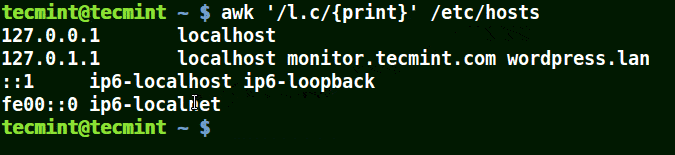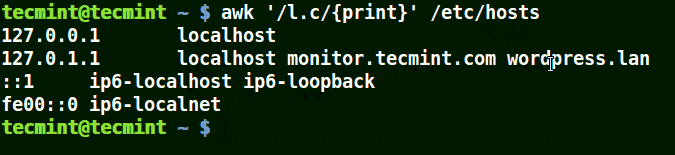
使用 awk 列印文件中匹配模式的字元串
在 awk 模式中使用字元 (*)
(LCTT 譯者註:此處原文作者理解有誤,感謝微信讀者「止此而已」的提醒,* 在此處表示其前一個字元重複零次或多次,所以實際上相當於 * 及前面的字元是無用的。)
在下面的例子中,將匹配包含 localhost、localnet、lines, capable 的字元串。將匹配帶有 c 字元的字元串。
# awk '/l*c/{print}' /etc/localhost
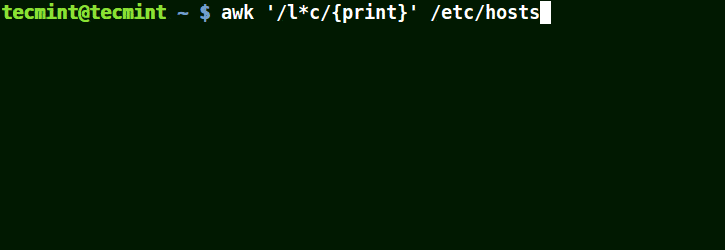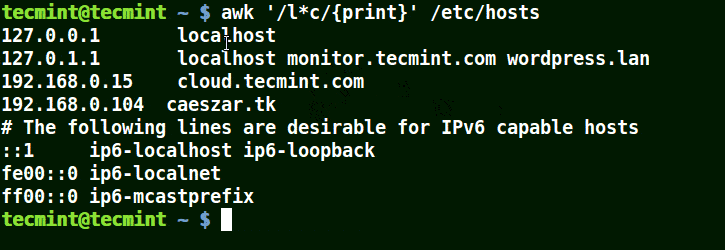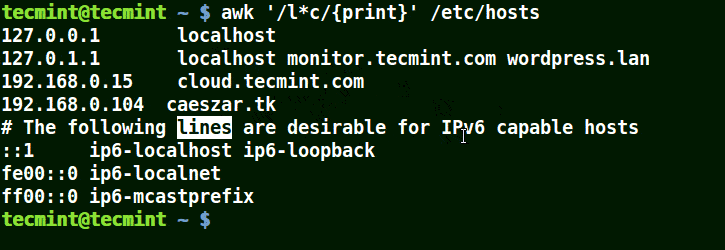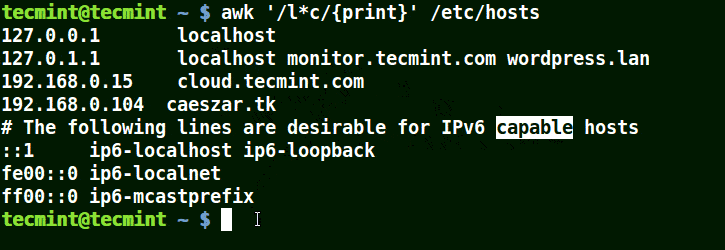
使用 awk 匹配文件中的字元串
你可能也意識到 (*) 將會嘗試匹配它可能檢測到的最長的匹配。
讓我們看一看可以證明這一點的例子,正則表達式 t*t 的意思是在下面的行中匹配以 t 開始和 t 結束的字元串:將匹配帶有 t 字元的字元串:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
當你使用模式 /t*t/ 時,會得到如下可能的結果:以下字元串只是有 t 字元而已:
this is t
this is tecmint
this is tecmint, where you get t
this is tecmint, where you get the best good t
this is tecmint, where you get the best good tutorials, how t
this is tecmint, where you get the best good tutorials, how tos, guides, t
this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
在 /t*t/ 中的通配符 (*) 將使得 awk 選擇匹配的最後一項:以下字元串只是有 t 字元而已:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
結合集合 [ character(s) ] 使用 awk
以集合 [al1] 為例,awk 將匹配文件 /etc/hosts 中所有包含字元 a 或 l 或 1 的字元串。
# awk '/[al1]/{print}' /etc/hosts
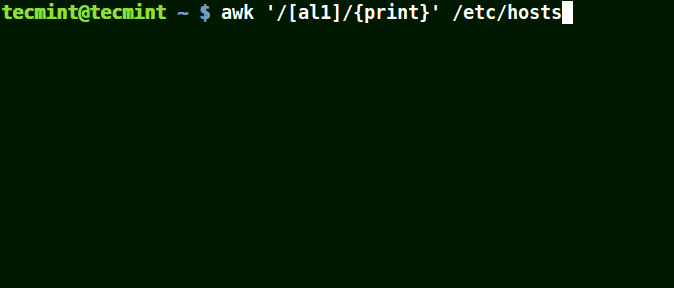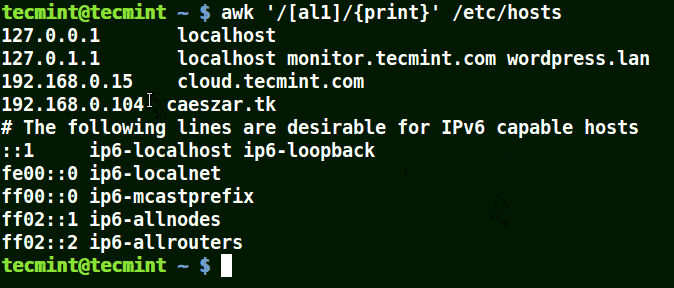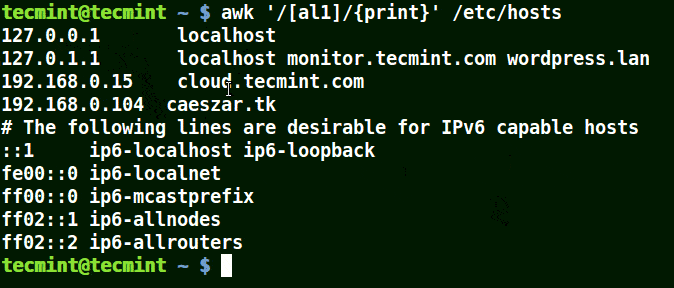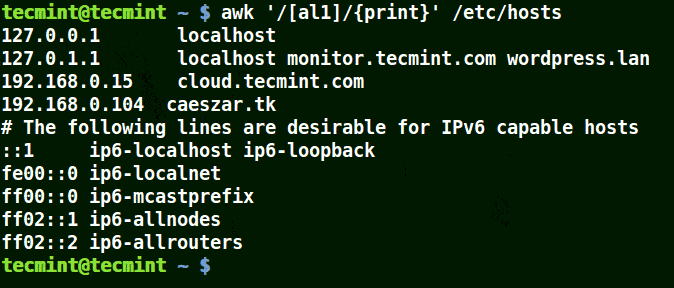
使用 awk 列印文件中匹配的字元
下一個例子匹配以 K 或 k 開始(非指行首是該字母),後面跟著一個 T 的字元串:
# awk '/[Kk]T/{print}' /etc/hosts

使用 awk 列印文件中匹配的字元
以範圍的方式指定字元
awk 所能理解的字元:
[0-9]代表一個單獨的數字[a-z]代表一個單獨的小寫字母[A-Z]代表一個單獨的大寫字母[a-zA-Z]代表一個單獨的字母[a-zA-Z 0-9]代表一個單獨的字母或數字
讓我們看看下面的例子:
# awk '/[0-9]/{print}' /etc/hosts
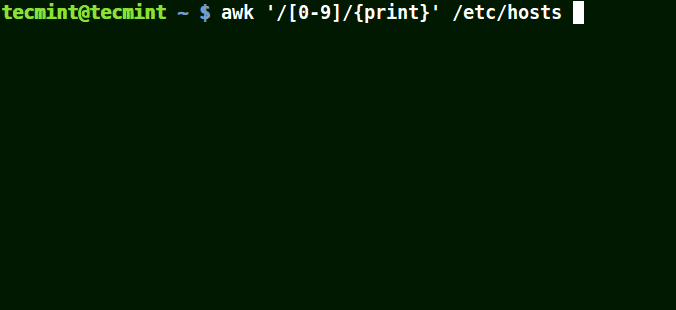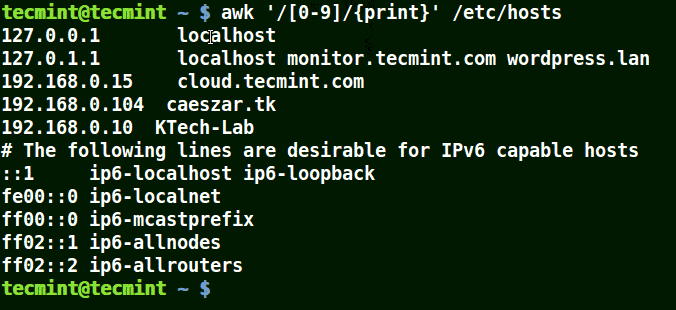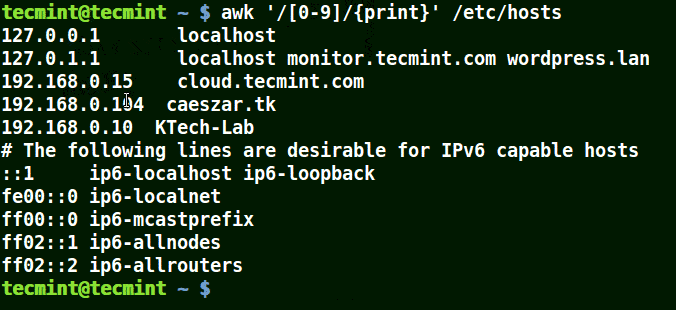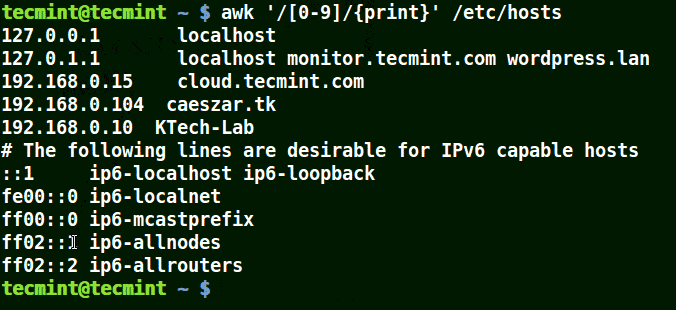
使用 awk 列印文件中匹配的數字
在上面的例子中,文件 /etc/hosts 中的所有行都至少包含一個單獨的數字 [0-9]。
結合元字元 (^) 使用 awk
在下面的例子中,它匹配所有以給定模式開頭的行:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
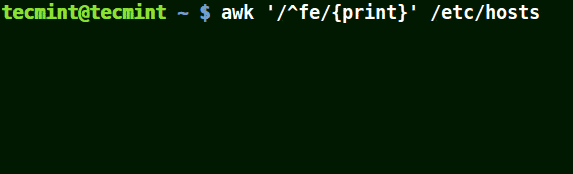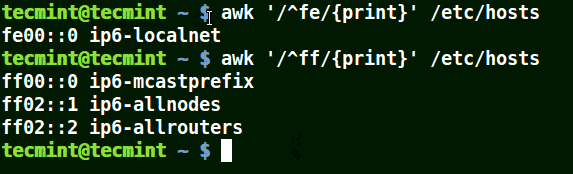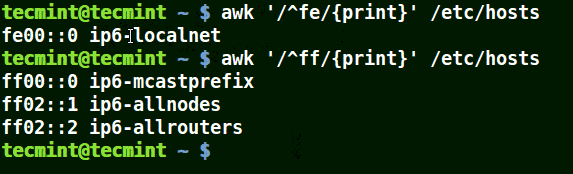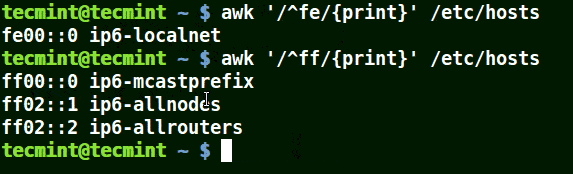
使用 awk 列印與模式匹配的行
結合元字元 ($) 使用 awk
它將匹配所有以給定模式結尾的行:
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
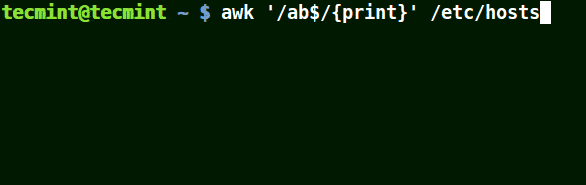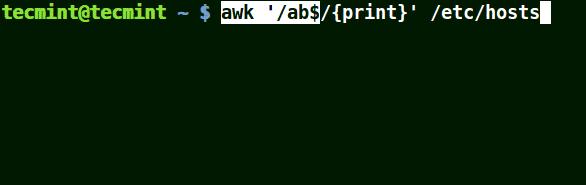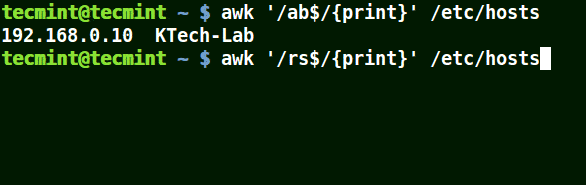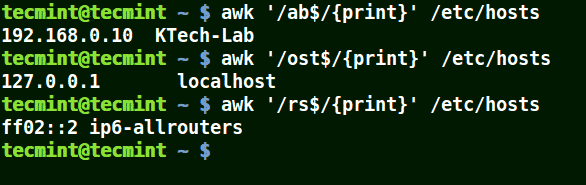
使用 awk 列印與模式匹配的字元串
結合轉義字元 () 使用 awk
它允許你將該轉義字元後面的字元作為文字,即理解為其字面的意思。
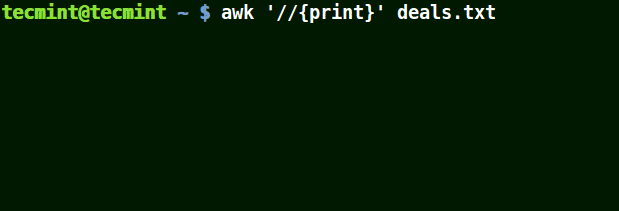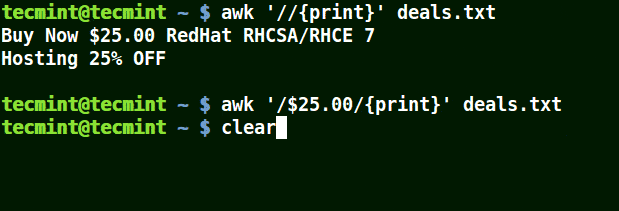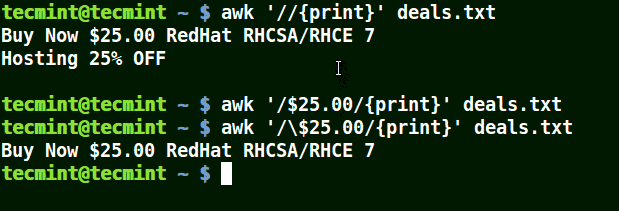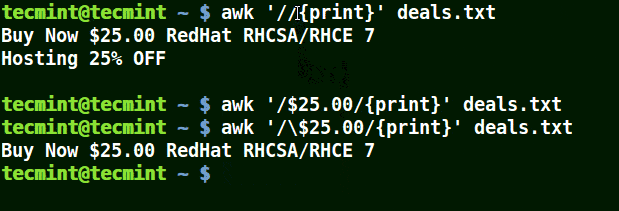
在下面的例子中,第一個命令列印出文件中的所有行,第二個命令中我想匹配具有 $25.00 的一行,但我並未使用轉義字元,因而沒有列印出任何內容。
第三個命令是正確的,因為一個這裡使用了一個轉義字元以轉義 $,以將其識別為 '$'(而非元字元)。
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
結合轉義字元使用 awk
總結
以上內容並不是 awk 命令用做過濾工具的全部,上述的示例均是 awk 的基礎操作。在下面的章節中,我將進一步介紹如何使用 awk 的高級功能。感謝您的閱讀,請在評論區貼出您的評論。
via: http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/
作者:Aaron Kili 譯者:wwy-hust 校對:wxy
本文轉載來自 Linux 中國: https://github.com/Linux-CN/archive
對這篇文章感覺如何?
You may also like






More in:Linux中國

捐贈 Let's Encrypt,共建安全的互聯網

Let's Encrypt 正式發布,已經保護 380 萬個域名

關於Linux防火牆iptables的面試問答

Lets Encrypt 已被所有主流瀏覽器所信任









