人工智能的巨大突破! AlphaGo 靠什么击败李世石?

在刚刚结束的 Google 围棋挑战赛第一天的比赛中,李世石输给了人工智能产品 AlphaGo。要知道李世石可是职业九段选手啊,AlphaGo 的胜利难道只是巧合还是另有原因? Linux Story 小编带你一起去看看 AlphaGo 背后的那些事。
何为 AlphaGo ?
AlphaGo 是 Google DeepMind 开发的围棋程序。在2015年10月,它成为第一个不借助让子,在全尺寸19×19的棋盘上击败职业围棋棋手的电脑围棋程序。
AlphaGo 官网:https://deepmind.com/alpha-go.html
李世石简介
李世乭(朝鲜语:이세돌,1983年3月2日-),韩国围棋九段棋手,成长于韩国全罗南道偏僻的飞禽岛,所以又被称为“飞禽岛少年”。因中文汉字无“乭”字(韩国自创字),故中文媒体多将其简化为“石”(李世石)。早年棋风锐利,擅长大规模的攻杀,成绩卓越,近年来随着年纪渐长与技术逐渐成熟,开始转变为全能棋风,能攻能守,刚柔并济成为一代棋界巨匠。李世乭厉害之处在于他下棋的风格飘渺灵幻,时常有神来之笔,兼有强大的战力且计算极为精准。同时他也有着高水准的心理质素,世界大赛上常在落后的情况下迎头赶上逆转拿下胜局。在2005到2010年期间与中国的围棋第一人古力九段有多次交锋,受到很大注意。
AlphaGo 背后的秘密
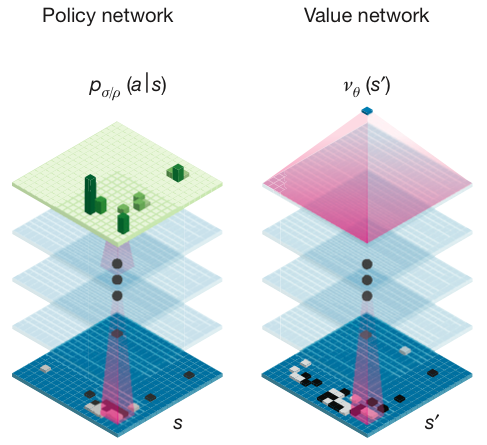
AlphaGo使用蒙特卡洛树搜索(Monte-Carlo tree search),借助价值网络(value network)与策略网络(policy network)这两种深度神经网络,通过价值网络来评估大量选点,并通过策略网络选择落点。AlphaGo最初通过模仿人类玩家,尝试匹配职业棋手的棋局,一旦它达到了一定的熟练程度,它开始和自己对弈大量棋局,使用强化学习进一步改善它。围棋无法仅通过寻找最佳步来解决;游戏一盘平均有150步,每一步平均有200种可选的下法,意味着有太多需要解决的可能性。
- 蒙特卡洛树搜索:一种博弈搜索算法。详情请见:https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
- 价值网络(value network):网络中节点存在值和连接。详情请见:https://en.wikipedia.org/wiki/Value_network
- 策略网络(policy network):用于选择落子。
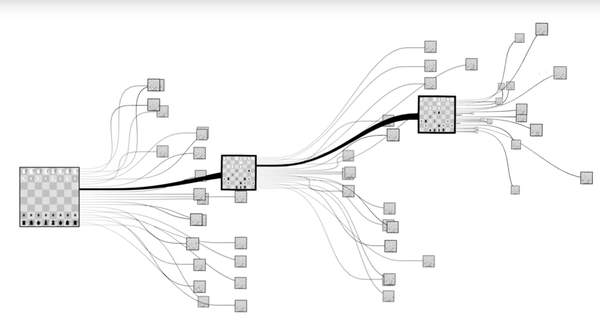
国际象棋的复杂度:
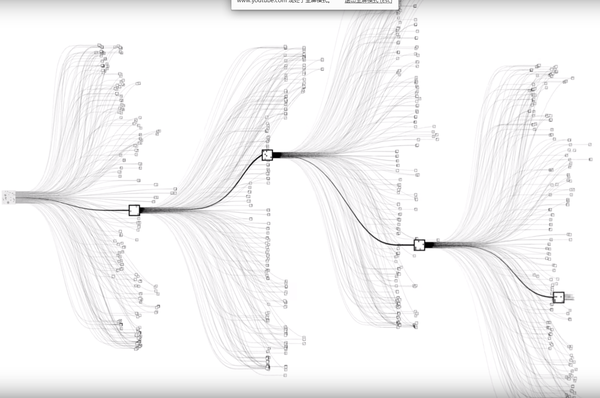
围棋的复杂度:
神经网络示意图:
与其说 AlphaGo 战胜了李世石,还不如说是人类战胜了自己。
Linux Story 提醒:更多详情请阅读原论文:
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
本文链接:
http://www.linuxstory.org/why-alphago-beated-lee-se-dol/
参考文献:
https://en.wikipedia.org/wiki/AlphaGo
对这篇文章感觉如何?
You may also like





1 Comment
Leave a reply
More in:人工智能

迈向开源另一步:微软将其深度学习工具包 CNTK 开源!

人工智能终将飞入寻常百姓家










图很赞!