解决八种Linux硬盘问题的技巧

1 - 错误: 设备上无剩余空间
当你的类UNIX系统磁盘写满了时你会在屏幕上看到这样的信息。本例中,我运行fallocate命令然后我的系统就会提示磁盘空间已经耗尽:
$ fallocate -l 1G test4.img
fallocate: test4.img: fallocate failed: No space left on device
第一步是运行df命令来查看一个有分区的文件系统的总磁盘空间和可用空间的信息:
$ df
或者试试可读性比较强的输出格式:
$ df -h
部分输出内容:
Filesystem Size Used Avail Use% Mounted on
/dev/sda6 117G 54G 57G 49% /
udev 993M 4.0K 993M 1% /dev
tmpfs 201M 264K 200M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 1002M 0 1002M 0% /run/shm
/dev/sda1 1.8G 115M 1.6G 7% /boot
/dev/sda7 4.7G 145M 4.4G 4% /tmp
/dev/sda9 9.4G 628M 8.3G 7% /var
/dev/sda8 94G 579M 89G 1% /ftpusers
/dev/sda10 4.0G 4.0G 0 100% /ftpusers/tmp
使用df命令输出可以清楚地发现,在 /dev/sda10 分区下总共4.0Gb的空间被全部写满了。
修复磁盘写满的问题
1.用gzip,bzip2或tar命令压缩未压缩的日志和其它文件:
gzip /ftpusers/tmp/*.log
bzip2 /ftpusers/tmp/large.file.name
2.在类UNIX系统中用rm命令删除不想要的文件:
rm -rf /ftpusers/tmp/*.bmp
rsync --remove-source-files -azv /ftpusers/tmp/*.mov /mnt/usbdisk/
rsync --remove-source-files -azv /ftpusers/tmp/*.mov server2:/path/to/dest/dir/
4.在类UNIX系统中找出最占磁盘空间的目录或文件:
du -a /ftpusers/tmp | sort -n -r | head -n 10
du -cks * | sort -rn | head
5.清空指定文件。这招对日志文件很有效:
truncate -s 0 /ftpusers/ftp.upload.log
### bash/sh等 ##
>/ftpusers/ftp.upload.log
## perl ##
perl -e'truncate "filename", LENGTH'
6.在Linux和UNIX中找出并删除显示着但已经被删除的大文件:
## 基于Linux/Unix/OSX/BSD等系统 ##
lsof -nP | grep '(deleted)'
## 只基于Linux ##
find /proc/*/fd -ls | grep '(deleted)'
清空它:
## 基于Linux/Unix/OSX/BSD等所有系统 ##
> "/path/to/the/deleted/file.name"
## 只基于Linux ##
> "/proc/PID-HERE/fd/FD-HERE"
2 - 文件系统是只读模式吗?
当你尝试新建或保存一个文件时,你可能最终得到诸如以下的错误:
$ cat > file
-bash: file: Read-only file system
运行mount命令来查看被挂载的文件系统是否处于只读状态:
$ mount
$ mount | grep '/ftpusers'
在基于Linux的系统中要修复这个问题,只需将这个处于只读状态的文件系统重新挂载即可:
# mount -o remount,rw /ftpusers/tmp
(LCTT 译注:如果硬盘由于硬件故障而 fallback 到只读模式,建议不要强制变回读写模式,而是赶快替换硬盘)
另外,我是这样用rw模式重新挂载FreeBSD 9.x服务器的根目录的:
# mount -o rw /dev/ad0s1a /
3 - Am I running out of inodes?
有时候,df命令能显示出磁盘有空余的空间但是系统却声称文件系统已经写满了。此时你需要用以下命令来检查能在文件系统中识别文件及其属性的索引节点:
$ df -i
$ df -i /ftpusers/
部分输出内容:
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda8 6250496 11568 6238928 1% /ftpusers
如上 /ftpusers 下有总计62,50,496KB大小的索引节点但是只有11,568KB被使用。你可以在 /ftpusers 位置下另外创建62,38,928KB大小的文件。如果你的索引节点100%被使用了,试试看以下的选项:
- 找出不想要的文件并删除它,或者把它移动到其它服务器上。
- 找出不想要的大文件并删除它,或者把它移动到其它服务器上。
(LCTT 译注:如果一个分区存储了太多的小文件,会出现 inode 用完而存储扇区还有空闲的情况,这种情况下要么清除小文件或在不需要独立访问的情况下将它们打包成一个大文件;要么将数据保存好之后重新分区,并设置分区的 -t news 属性,增加 inode 分配)
4 - 我的硬盘驱动器宕了吗?
日志文件中的输入/输出错误(例如 /var/log/messages)说明硬盘出了一些问题并且可能已经失效,你可以用smartctl命令来查看硬盘的错误,这是一个在类UNIX系统下控制和监控硬盘状态的一个命令。语法如下:
smartctl -a /dev/DEVICE
# 在Linux服务器下检查 /dev/sda
smartctl -a /dev/sda
你也可以用"Disk Utility"这个软件来获得同样的信息。
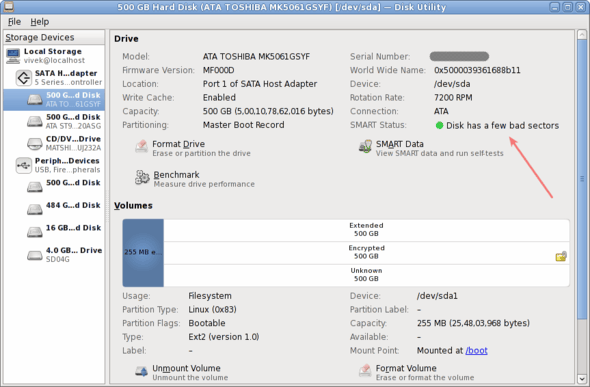
图 01: Gnome磁盘工具(Applications > System Tools > Disk Utility)
注意: 不要对S.M.A.R.T.工具期望太高,它在某些状况下无法工作,我们要定期做备份。
5 - 我的硬盘驱动器和服务器是不是太热了?
高温会引起服务器低效,所以你需要把服务器和磁盘维持在一个平稳适当的温度,高温甚至能导致服务器宕机或损坏文件系统和磁盘。用hddtemp或smartctl功能,通过从支持S.M.A.R.T.功能的硬盘上读取数据的方式,从而查出你的Linux或基于UNIX系统上的硬盘温度。只有现代硬驱动器有温度传感器。hddtemp功能也支持从SCSI驱动器读取S.M.A.R.T.信息。hddtemp能作为一个简单的命令行工具或守护程序来从所有服务器中获取信息:
hddtemp /dev/DISK
hddtemp /dev/sg0
部分输出内容如下:
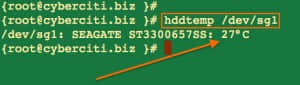
图 02: hddtemp正在运行
你也可以像下面显示的那样使用smartctl命令:
smartctl -d ata -A /dev/sda | grep -i temperature
我怎么获取CPU的温度
你可以使用Linux硬件监控工具,例如像用基于Linux系统的lm_sensor功能来获取CPU温度:
sensors
Debian服务器的部分输出内容:
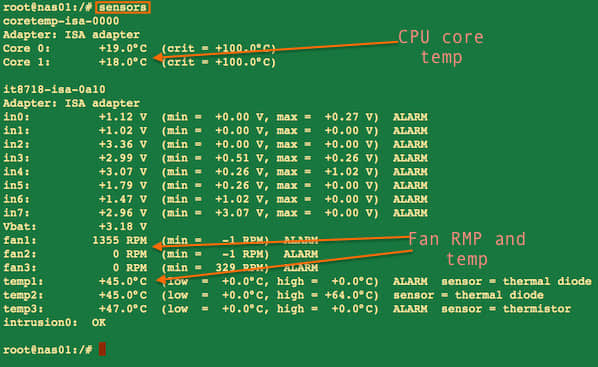
图 03: sensors命令提供了一台Linux计算机的CPU核心温度和其它信息
6 - 处理损坏的文件系统
服务器上的文件系统可能会因为硬件重启或一些其它的错误比如坏的扇区而损坏。你可以用fsck命令来修复损坏的文件系统:
umount /ftpusers
fsck -y /dev/sda8
来看看怎么应对Linux文件系统故障的更多信息。
7 - 处理Linux中的软阵列
输入以下命令来查看Linux软阵列的最近状态:
## 获得 /dev/md0 上磁盘阵列的具体内容 ##
mdadm --detail /dev/md0
## 查看状态 ##
cat /proc/mdstat
watch cat /proc/mdstat
部分输出内容:
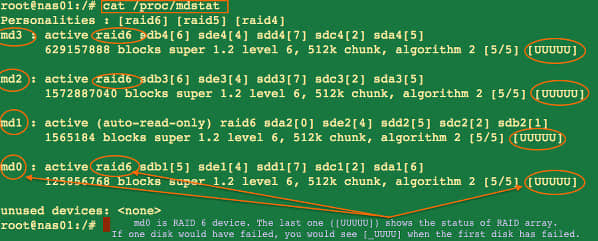
图 04: 查看Linux软阵列状态命令
你需要把有故障的硬件驱动器更换掉,别删错了。本例中,我更换了 /dev/sdb (RAID 6中的第二个硬件驱动器)。没必要依靠离线存储文件来修复Linux上的磁盘阵列,因为这只在你的服务器支持热插拔硬盘的情况下才能工作:
## 从一个md0阵列中删除磁盘 ##
mdadm --manage /dev/md0 --fail /dev/sdb1
mdadm --manage /dev/md0 --remove /dev/sdb1
# 对 /dev/sdbX 的剩余部分做相同操作 ##
# 如果不是热插拔硬盘就执行关机操作 ##
shutdown -h now
## 从 /dev/sda 复制分区表至新的 /dev/sdb 下 ##
sfdisk -d /dev/sda | sfdisk /dev/sdb
fdisk -l
## 添加 ##
mdadm --manage /dev/md0 --add /dev/sdb1
# 对 /dev/sdbX 的剩余部分做相同操作 ##
# 现在md0会再次同步,通过显示屏查看 ##
watch cat /proc/mdstat
来看看加快Linux磁盘阵列同步速度的小贴士来获取更多信息。
8 - 处理硬阵列
你可以用samrtctl命令或者供应商特定的命令来查看磁盘阵列和你所管理的磁盘的状态:
## SCSI磁盘
smartctl -d scsi --all /dev/sgX
## Adaptec磁盘阵列
/usr/StorMan/arcconf getconfig 1
## 3ware磁盘阵列
tw_cli /c0 show
对照供应商特定文档来更换你的故障磁盘。
监控磁盘的健康状况
来看看我们先前的教程:
- Monitoring hard disk health with smartd under Linux or UNIX operating systems
- Shell script to watch the disk space
- UNIX get an alert when disk is full
- Monitor UNIX / Linux server disk space with a shell scrip
- Perl script to monitor disk space and send an email
- NAS backup server disk monitoring shell script
结论
我希望以上这些小贴士会帮助你改善在基于Linux/Unix服务器上的系统磁盘问题。我还建议执行一个好的备份计划从而有能力从磁盘故障、意外的文件删除操作、文件损坏和服务器完全被破坏等意外情况中恢复:
- Debian / Ubuntu: Install Duplicity for encrypted backup in cloud
- HowTo: Backup MySQL databases, web server files to a FTP server automatically
- How To Set Red hat & CentOS Linux remote backup / snapshot server
- Debian / Ubuntu Linux install and configure remote filesystem snapshot with rsnapshot incremental backup utility
- Linux Tape backup with mt And tar command tutorial
via: http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/
本文转载来自 Linux 中国: https://github.com/Linux-CN/archive
对这篇文章感觉如何?
You may also like






More in:Linux中国

捐赠 Let's Encrypt,共建安全的互联网

Let's Encrypt 正式发布,已经保护 380 万个域名

关于Linux防火墙iptables的面试问答

Lets Encrypt 已被所有主流浏览器所信任









