GitHub 的 DNS 基础设施

在 GitHub,我们最近从头改进了 DNS。这包括了我们如何与外部 DNS 提供商交互以及我们如何在内部向我们的主机提供记录。为此,我们必须设计和构建一个新的 DNS 基础设施,它可以随着 GitHub 的增长扩展并跨越多个数据中心。
以前,GitHub 的 DNS 基础设施相当简单直接。它包括每台服务器上本地的、只具备转发功能的 DNS 缓存服务器,以及一对被所有这些主机使用的缓存服务器和权威服务器主机。这些主机在内部网络以及公共互联网上都可用。我们在缓存守护程序中配置了 区域 存根 ,以在本地进行查询,而不是在互联网上进行递归。我们还在我们的 DNS 提供商处设置了 NS 记录,它们将特定的内部 域 指向这对主机的公共 IP,以便我们网络外部的查询。
这个配置使用了很多年,但它并非没有缺点。许多程序对于解析 DNS 查询非常敏感,我们遇到的任何性能或可用性问题在最好的情况下也会导致服务排队和性能降级,而最坏情况下客户会遭遇服务中断。配置和代码的更改可能会导致查询率发生大幅度的意外变化。因此超出这两台主机的扩展成为了一个问题。由于这些主机的网络配置,如果我们只是继续添加 IP 和主机的话存在一些本身的问题。在试图解决和补救这些问题的同时,由于缺乏测量指标和可见性,老旧的系统难以识别问题的原因。在许多情况下,我们使用 tcpdump 来识别有问题的流量和查询。另一个问题是在公共 DNS 服务器上运行,我们处于泄露内部网络信息的风险之下。因此,我们决定建立更好的东西,并开始确定我们对新系统的要求。
我们着手设计一个新的 DNS 基础设施,以改善上述包括扩展和可见性在内的运维问题,并引入了一些额外的需求。我们希望通过外部 DNS 提供商继续运行我们的公共 DNS 域,因此我们构建的系统需要与供应商无关。此外,我们希望该系统能够服务于我们的内部和外部域,这意味着内部域仅在我们的内部网络上可用,除非另有特别配置,而外部域也不用离开我们的内部网络就可解析。我们希望新的 DNS 架构不但可以基于部署的工作流进行更改,并可以通过我们的仓库和配置系统使用 API 自动更改 DNS 记录。新系统不能有任何外部依赖,太依赖于 DNS 功能将会陷入级联故障,这包括连接到其他数据中心和其中可能有的 DNS 服务。我们的旧系统将缓存服务器和权威服务器在同一台主机上混合使用。我们想转到具有独立角色的分层设计。最后,我们希望系统能够支持多数据中心环境,无论是 EC2 还是裸机。
实现
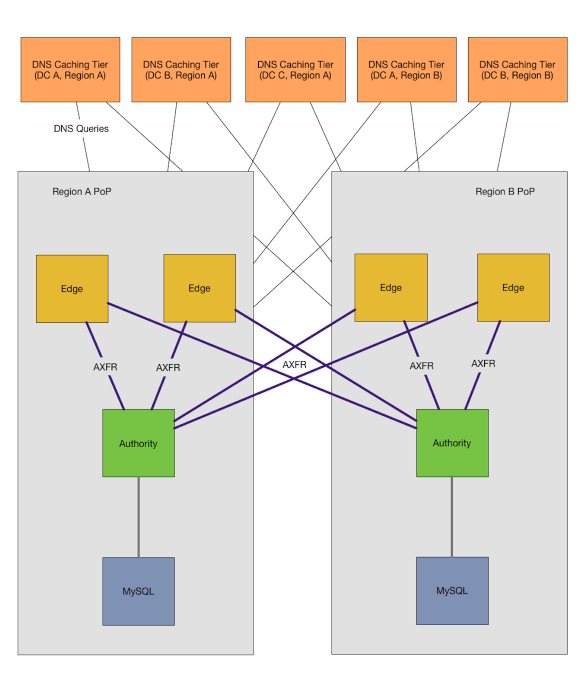
为了构建这个系统,我们确定了三类主机: 缓存主机 、 边缘主机 和 权威主机 。缓存主机作为 递归解析器 和 DNS “路由器” 缓存来自边缘层的响应。边缘层运行 DNS 权威守护程序,用于响应缓存层对 DNS 区域 的请求,其被配置为来自权威层的 区域传输 。权威层作为隐藏的 DNS 主服务器 ,作为 DNS 数据的规范来源,为来自边缘主机的 区域传输 提供服务,并提供用于创建、修改或删除记录的 HTTP API。
在我们的新配置中,缓存主机存在于每个数据中心中,这意味着应用主机不需要穿过数据中心边界来检索记录。缓存主机被配置为将 区域 映射到其 地域 内的边缘主机,以便将我们的内部 区域 路由到我们自己的主机。未明确配置的任何 区域 将通过互联网递归解析。
边缘主机是地域性的主机,存在我们的网络边缘 PoP( 存在点 )内。我们的 PoP 有一个或多个依赖于它们进行外部连接的数据中心,没有 PoP 数据中心将无法访问互联网,互联网也无法访问它们。边缘主机对所有的权威主机执行 区域传输 ,无论它们存在什么 地域 或 位置 ,并将这些区域存在本地的磁盘上。
我们的权威主机也是地域性的主机,只包含适用于其所在 地域 的 区域 。我们的仓库和配置系统决定一个 区域 存放在哪个 地域性权威主机 ,并通过 HTTP API 服务来创建和删除记录。 OctoDNS 将区域映射到地域性权威主机,并使用相同的 API 创建静态记录,以及确保动态源处于同步状态。对于外部域 (如 github.com),我们有另外一个单独的权威主机,以允许我们可以在连接中断期间查询我们的外部域。所有记录都存储在 MySQL 中。
可运维性
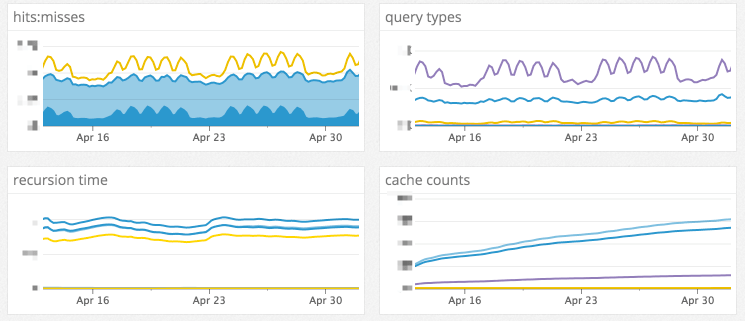
迁移到更现代的 DNS 基础设施的巨大好处是可观察性。我们的旧 DNS 系统几乎没有指标,只有有限的日志。决定使用哪些 DNS 服务器的一个重要因素是它们所产生的指标的广度和深度。我们最终用 Unbound 作为缓存主机,NSD 作为边缘主机,PowerDNS 作为权威主机,所有这些都已在比 GitHub 大得多的 DNS 基础架构中得到了证实。
当在我们的裸机数据中心运行时,缓存通过私有的 任播 IP 访问,从而使之可以到达最近的可用缓存主机。缓存主机已经以机架感知的方式部署,在它们之间提供了一定程度的平衡负载,并且与一些电源和网络故障模式相隔离。当缓存主机出现故障时,通常将用其进行 DNS 查询的服务器现在将自动路由到下一个最接近的缓存主机,以保持低延迟并提供对某些故障模式的容错。任播允许我们扩展单个 IP 地址后面的缓存数量,这与先前的配置不同,使得我们能够按 DNS 需求量运行尽可能多的缓存主机。
无论地域或位置如何,边缘主机使用权威层进行区域传输。我们的 区域 并没有大到在每个 地域 保留所有 区域 的副本成为问题。(LCTT 译注:此处原文“Our zones are not large enough that keeping a copy of all of them in every region is a problem.”,根据上下文理解而翻译。)这意味着对于每个区域,即使某个地域处于脱机状态,或者上游服务提供商存在连接问题,所有缓存服务器都可以访问具备所有区域的本地副本的本地边缘服务器。这种变化在面对连接问题方面已被证明是相当有弹性的,并且在不久前本来会导致客户面临停止服务的故障期间帮助保持 GitHub 可用。
那些区域传输包括了内部和外部域从它们相应的权威服务器进行的传输。正如你可能会猜想像 github.com 这样的区域是外部的,像 github.net 这样的区域通常是内部的。它们之间的区别仅在于我们使用的类型和存储在其中的数据。了解哪些区域是内部和外部的,为我们在配置中提供了一些灵活性。
$ dig +short github.com
192.30.253.112
192.30.253.113
公共 区域 被同步到外部 DNS 提供商,并且是 GitHub 用户每天使用的 DNS 记录。另外,公共区域在我们的网络中是完全可解析的,而不需要与我们的外部提供商进行通信。这意味着需要查询 api.github.com 的任何服务都可以这样做,而无需依赖外部网络连接。我们还使用了 Unbound 的 stub-first 配置选项,它给了我们第二次查询的机会,如果我们的内部 DNS 服务由于某些原因在外部查询失败,则可以进行第二次查找。
$ dig +short time.github.net
10.127.6.10
大部分的 github.net 区域是完全私有的,无法从互联网访问,它只包含 RFC 1918 中规定的 IP 地址。每个地域和站点都划分了私有区域。每个地域和/或站点都具有适用于该位置的一组子区域,子区域用于管理网络、服务发现、特定的服务记录,并且还包括在我们仓库中的配置主机。私有区域还包括 PTR 反向查找区域。
总结
用一个新系统替换可以为数百万客户提供服务的旧系统并不容易。使用实用的、基于需求的方法来设计和实施我们的新 DNS 系统,才能打造出一个能够迅速有效地运行、并有望与 GitHub 一起成长的 DNS 基础设施。
想帮助 GitHub SRE 团队解决有趣的问题吗?我们很乐意你加入我们。在这申请。
via: https://githubengineering.com/dns-infrastructure-at-github/
作者:Joe Williams 译者:geekpi 校对:wxy
本文转载来自 Linux 中国: https://github.com/Linux-CN/archive
对这篇文章感觉如何?
You may also like






More in:Linux中国

捐赠 Let's Encrypt,共建安全的互联网

Let's Encrypt 正式发布,已经保护 380 万个域名

关于Linux防火墙iptables的面试问答

Lets Encrypt 已被所有主流浏览器所信任









