Linux 中的 DTrace :BPF 进入 4.9 内核

用于 Linux 的追踪项目有很多,但是这个最终被合并进 Linux 内核的技术从一开始就根本不是一个追踪项目:它是最开始是用于 伯克利包过滤器 (BPF)的增强功能。这些补丁允许 BPF 重定向数据包,从而创建软件定义网络(SDN)。久而久之,对事件追踪的支持就被添加进来了,使得程序追踪可用于 Linux 系统。
尽管目前 BPF 没有像 DTrace 一样的高级语言,但它所提供的前端已经足够让我创建很多 BPF 工具了,其中有些是基于我以前的 DTraceToolkit。这个帖子将告诉你怎么去用这些 BPF 提供的前端工具,以及畅谈这项技术将会何去何从。
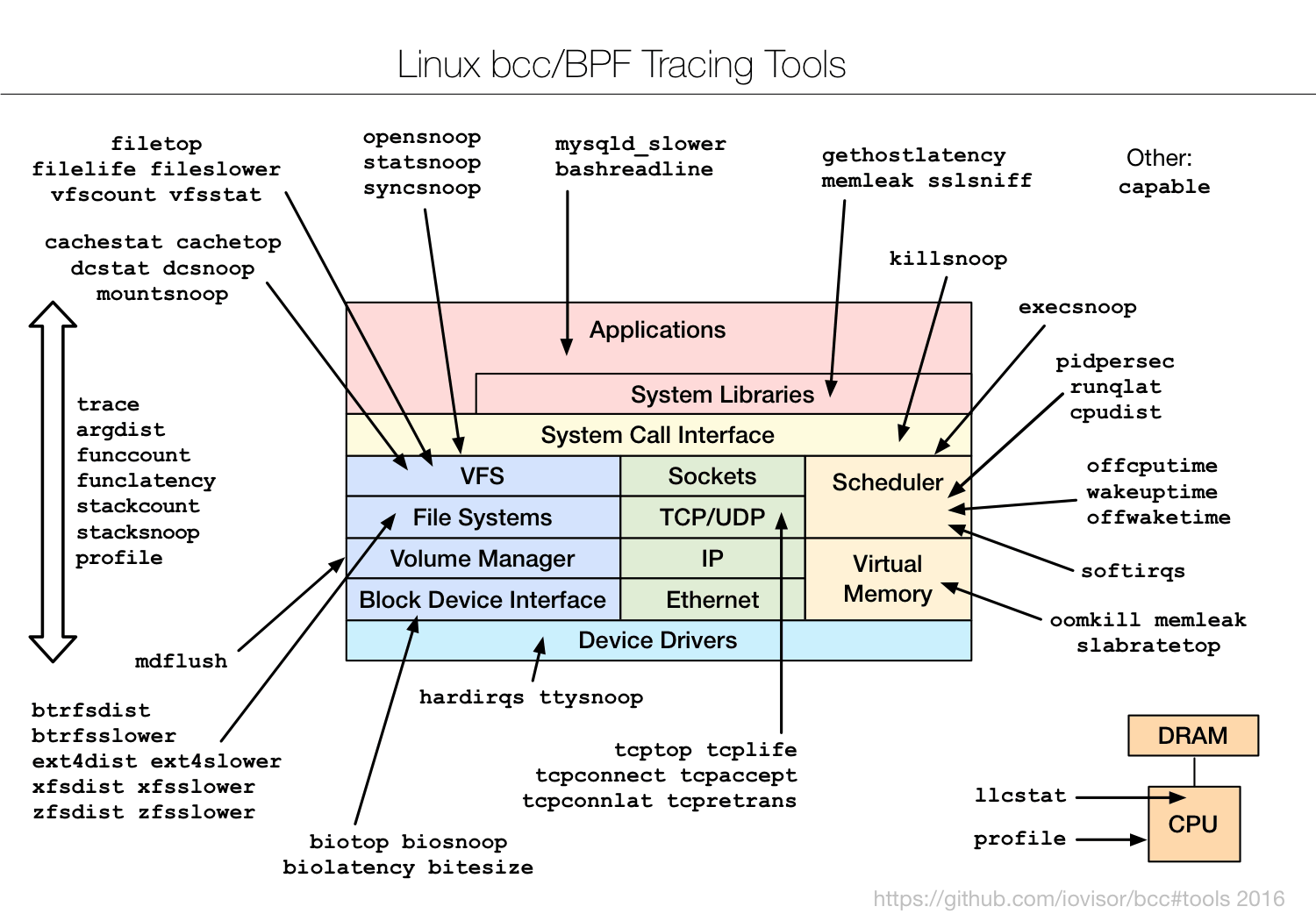
示例
我已经将基于 BPF 的追踪工具添加到了开源的 bcc 项目里(感谢 PLUMgrid 公司的 Brenden Blanco 带领 bcc 项目的发展)。详见 bcc 安装 手册。它会在 /usr/share/bcc/tools 目录下添加一系列工具,包括接下来的那些工具。
捕获新进程:
# execsnoop
PCOMM PID RET ARGS
bash 15887 0 /usr/bin/man ls
preconv 15894 0 /usr/bin/preconv -e UTF-8
man 15896 0 /usr/bin/tbl
man 15897 0 /usr/bin/nroff -mandoc -rLL=169n -rLT=169n -Tutf8
man 15898 0 /usr/bin/pager -s
nroff 15900 0 /usr/bin/locale charmap
nroff 15901 0 /usr/bin/groff -mtty-char -Tutf8 -mandoc -rLL=169n -rLT=169n
groff 15902 0 /usr/bin/troff -mtty-char -mandoc -rLL=169n -rLT=169n -Tutf8
groff 15903 0 /usr/bin/grotty
硬盘 I/O 延迟的柱状图:
# biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 96 |************************************ |
2 -> 3 : 25 |********* |
4 -> 7 : 29 |*********** |
8 -> 15 : 62 |*********************** |
16 -> 31 : 100 |**************************************|
32 -> 63 : 62 |*********************** |
64 -> 127 : 18 |****** |
追踪慢于 5 毫秒的 ext4 常见操作:
# ext4slower 5
Tracing ext4 operations slower than 5 ms
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
21:49:45 supervise 3570 W 18 0 5.48 status.new
21:49:48 supervise 12770 R 128 0 7.55 run
21:49:48 run 12770 R 497 0 16.46 nsswitch.conf
21:49:48 run 12770 R 1680 0 17.42 netflix_environment.sh
21:49:48 run 12770 R 1079 0 9.53 service_functions.sh
21:49:48 run 12772 R 128 0 17.74 svstat
21:49:48 svstat 12772 R 18 0 8.67 status
21:49:48 run 12774 R 128 0 15.76 stat
21:49:48 run 12777 R 128 0 7.89 grep
21:49:48 run 12776 R 128 0 8.25 ps
21:49:48 run 12780 R 128 0 11.07 xargs
21:49:48 ps 12776 R 832 0 12.02 libprocps.so.4.0.0
21:49:48 run 12779 R 128 0 13.21 cut
[...]
追踪新建的 TCP 活跃连接(connect()):
# tcpconnect
PID COMM IP SADDR DADDR DPORT
1479 telnet 4 127.0.0.1 127.0.0.1 23
1469 curl 4 10.201.219.236 54.245.105.25 80
1469 curl 4 10.201.219.236 54.67.101.145 80
1991 telnet 6 ::1 ::1 23
2015 ssh 6 fe80::2000:bff:fe82:3ac fe80::2000:bff:fe82:3ac 22
通过跟踪 getaddrinfo()/gethostbyname() 库的调用来追踪 DNS 延迟:
# gethostlatency
TIME PID COMM LATms HOST
06:10:24 28011 wget 90.00 www.iovisor.org
06:10:28 28127 wget 0.00 www.iovisor.org
06:10:41 28404 wget 9.00 www.netflix.com
06:10:48 28544 curl 35.00 www.netflix.com.au
06:11:10 29054 curl 31.00 www.plumgrid.com
06:11:16 29195 curl 3.00 www.facebook.com
06:11:25 29404 curl 72.00 foo
06:11:28 29475 curl 1.00 foo
按类别划分 VFS 操作的时间间隔统计:
# vfsstat
TIME READ/s WRITE/s CREATE/s OPEN/s FSYNC/s
18:35:32: 231 12 4 98 0
18:35:33: 274 13 4 106 0
18:35:34: 586 86 4 251 0
18:35:35: 241 15 4 99 0
对一个给定的 PID,通过内核和用户堆栈轨迹来追踪 CPU 处理之外的时间(由内核进行统计):
# offcputime -d -p 24347
Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to end.
^C
[...]
ffffffff810a9581 finish_task_switch
ffffffff8185d385 schedule
ffffffff81085672 do_wait
ffffffff8108687b sys_wait4
ffffffff81861bf6 entry_SYSCALL_64_fastpath
--
00007f6733a6b64a waitpid
- bash (24347)
4952
ffffffff810a9581 finish_task_switch
ffffffff8185d385 schedule
ffffffff81860c48 schedule_timeout
ffffffff810c5672 wait_woken
ffffffff8150715a n_tty_read
ffffffff815010f2 tty_read
ffffffff8122cd67 __vfs_read
ffffffff8122df65 vfs_read
ffffffff8122f465 sys_read
ffffffff81861bf6 entry_SYSCALL_64_fastpath
--
00007f6733a969b0 read
- bash (24347)
1450908
追踪 MySQL 查询延迟(通过 USDT 探针):
# mysqld_qslower `pgrep -n mysqld`
Tracing MySQL server queries for PID 14371 slower than 1 ms...
TIME(s) PID MS QUERY
0.000000 18608 130.751 SELECT * FROM words WHERE word REGEXP '^bre.*n$'
2.921535 18608 130.590 SELECT * FROM words WHERE word REGEXP '^alex.*$'
4.603549 18608 24.164 SELECT COUNT(*) FROM words
9.733847 18608 130.936 SELECT count(*) AS count FROM words WHERE word REGEXP '^bre.*n$'
17.864776 18608 130.298 SELECT * FROM words WHERE word REGEXP '^bre.*n$' ORDER BY word
监测 pam 库并使用多种追踪工具观察登录请求:
# trace 'pam:pam_start "%s: %s", arg1, arg2'
TIME PID COMM FUNC -
17:49:45 5558 sshd pam_start sshd: root
17:49:47 5662 sudo pam_start sudo: root
17:49:49 5727 login pam_start login: bgregg
bcc 项目里的很多工具都有帮助信息(-h 选项),并且都应该包含有示例的 man 页面和文本文件。
必要性
2014 年,Linux 追踪程序就有一些内核相关的特性(来自 ftrace 和 pref_events),但是我们仍然要转储并报告进程数据,这种几十年前的老技术有很多的限制。你不能频繁地访问进程名、函数名、堆栈轨迹或内核中的任意的其它数据。你不能在将变量保存到一个监测事件里,又在另一个事件里访问它们,这意味着你不能在你需要的地方计算延迟(或者说时间增量)。你也不能创建一个内核内部的延迟柱状图,也不能追踪 USDT 探针,甚至不能写个自定义的程序。DTrace 可以做到所有这些,但仅限于 Solaris 或 BSD 系统。在 Linux 系统中,有些不在主线内核的追踪器,比如 SystemTap 就可以满足你的这些需求,但它也有自身的不足。(理论上说,你可以写一个基于探针的内核模块来满足需求-但实际上没人这么做。)
2014 年我加入了 Netflix cloud performance 团队。做了这么久的 DTrace 方面的专家,转到 Linux 对我来说简直不可思议。但我确实这么做了,而且遇到了巨大的挑战:在应用快速变化、采用微服务架构和分布式系统的情况下,调优 Netflix cloud。有时要用到系统追踪,而我之前是用的 DTrace。在 Linux 系统上可没有 DTrace,我就开始用 Linux 内核内建的 ftrace 和 perf_events 工具,构建了一个追踪工具(perf-tools)。这些工具很有用,但有些工作还是没法完成,尤其是延迟柱状图以及堆栈踪迹计数。我们需要的是内核追踪的可程序化。
发生了什么?
BPF 将程序化的功能添加到现有的内核追踪工具中(tracepoints、kprobes、uprobes)。在 Linux 4.x 系列的内核里,这些功能大大加强了。
时间采样是最主要的部分,它被 Linux 4.9-rc1 所采用(patchset)。十分感谢 Alexei Starovoitov(在 Facebook 致力于 BPF 的开发),他是这些 BPF 增强功能的主要开发者。
Linux 内核现在内建有以下这些特性(自 2.6 版本到 4.9 版本之间增加):
- 内核级的动态追踪(BPF 对
kprobes的支持) - 用户级的动态追踪(BPF 对
uprobes的支持) - 内核级的静态追踪(BPF 对
tracepoints的支持) - 时间采样事件(BPF 的
pref_event_open) - PMC 事件(BPF 的
pref_event_open) - 过滤器(通过 BPF 程序)
- 调试输出(
bpf_trace_printk()) - 按事件输出(
bpf_perf_event_output()) - 基础变量(全局的和每个线程的变量,基于 BPF 映射)
- 关联数组(通过 BPF 映射)
- 频率计数(基于 BPF 映射)
- 柱状图(2 的冥次方、线性及自定义,基于 BPF 映射)
- 时间戳和时间增量(
bpf_ktime_get_ns(),和 BPF 程序) - 内核态的堆栈轨迹(BPF 栈映射)
- 用户态的堆栈轨迹 (BPF 栈映射)
- 重写 ring 缓存(
pref_event_attr.write_backward)
我们采用的前端是 bcc,它同时提供 Python 和 lua 接口。bcc 添加了:
- 用户级静态追踪(基于
uprobes的 USDT 探针) - 调试输出(Python 中调用
BPF.trace_pipe()和BPF.trace_fields()函数 ) - 按事件输出(
BPF_PERF_OUTPUT宏和BPF.open_perf_buffer()) - 间隔输出(
BPF.get_table()和table.clear()) - 打印柱状图(
table.print_log2_hist()) - 内核级的 C 结构体导航(bcc 重写器映射到
bpf_probe_read()函数) - 内核级的符号解析(
ksym()、ksymaddr()) - 用户级的符号解析(
usymaddr()) - BPF 跟踪点支持(通过
TRACEPOINT_PROBE) - BPF 堆栈轨迹支持(包括针对堆栈框架的
walk方法) - 其它各种辅助宏和方法
- 例子(位于
/examples目录) - 工具(位于
/tools目录) - 教程(
/docs/tutorial*.md) - 参考手册(
/docs/reference_guide.md)
直到最新也是最主要的特性被整合进来,我才开始写这篇文章,现在它在 4.9-rc1 内核中。我们还需要去完成一些次要的东西,还有另外一些事情要做,但是现在我们所拥有的已经值得欢呼了。现在 Linux 拥有了内建的高级追踪能力。
安全性
设计 BPF 及其增强功能时就考虑到生产环境级安全,它被用在大范围的生产环境里。不过你想的话,你还是可以找到一个挂起内核的方法。这种情况是偶然的,而不是必然,类似的漏洞会被快速修复,尤其是当 BPF 合并入了 Linux。因为 Linux 可是公众的焦点。
在开发过程中我们碰到了一些非 BPF 的漏洞,它们需要被修复:rcu 不可重入,这可能导致内核由于 funccount 挂起,在 4.6 内核版本中这个漏洞被 “bpf: map pre-alloc” 补丁集所修复,旧版本内核的漏洞 bcc 有个临时处理方案。还有一个是 uprobe 的内存计算问题,这导致 uprobe 分配内存失败,在 4.8 内核版本这个漏洞由 “uprobes: Fix the memcg accounting” 补丁所修复,并且该补丁还将被移植到之前版本的内核中(例如,它现在被移植到了 4.4.27 和 4.4.0-45.66 版本中)。
为什么 Linux 追踪用了这么久才加进来?
首要任务被分到了若干追踪器中间:这些不是某个追踪器单个的事情。想要了解更多关于这个或其它方面的问题,可以看一看我在 2014 年 tracing summit 上的讲话。我忽视了部分方案的反面影响:有些公司发现其它追踪器(SystemTap 和 LTTng)能满足他们的需求,尽管他们乐于听到 BPF 的开发进程,但考虑到他们现有的解决方案,帮助 BPF 的开发就不那么重要了。
BPF 仅在近两年里在追踪领域得到加强。这一过程原本可以更快的,但早期缺少全职从事于 BPF 追踪的工程师。Alexei Starovoitov (BPF 领导者),Brenden Blanco (bcc 领导者),我还有其它一些开发者,都有其它的事情要做。我在 Netflix 公司花了大量时间(志愿地),大概有 7% 的时间是花在 BPF 和 bcc 上。某种程度上这不是我的首要任务,因为我还有自己的工作(包括我的 perf-tools,一个可以工作在旧版本内核上的程序)。
现在BPF 追踪器已经推出了,已经有科技公司开始寻找会 BPF 的人了。但我还是推荐 Netflix 公司。(如果你为了 BPF 而要聘请我,那我还是十分乐于待在 Netflix 公司的!)
使用简单
DTrace 和 bcc/BPF 现在的最大区别就是哪个更好使用。这取决于你要用 BPF 追踪做什么了。如果你要
- 使用 BPF 工具/度量:应该是没什么区别的。工具的表现都差不多,图形用户界面都能取得类似度量指标。大部分用户通过这种方式使用 BPF。
- 开发工具/度量:bcc 的开发可难多了。DTrace 有一套自己的简单语言,D 语音,和 awk 语言相似,而 bcc 使用已有的语言(C 语言,Python 和 lua)及其类库。一个用 C 和 Python 写的 bcc 工具与仅仅用 D 语言写出来的工具相比,可能要多十多倍行数的代码,或者更多。但是很多 DTrace 工具用 shell 封装来提供参数和差错检查,会让代码变得十分臃肿。编程的难处是不同的:重写 bcc 更需要巧妙性,这导致某些脚本更加难开发。(尤其是
bpf_probe_read()这类的函数,需要了解更多 BPF 的内涵知识)。当计划改进 bcc 时,这一情形将得到改善。 - 运行常见的命令:十分相近。通过
dtrace命令,DTrace 能做很多事,但 bcc 有各种工具,trace、argdist、funccount、funclatency等等。 - 编写自定义的特殊命令:使用 DTrace 的话,这就没有必要了。允许定制消息快速传递和系统快速响应,DTrace 的高级分析很快。而 bcc 现在受限于它的多种工具以及它们的适用范围。
简单来说,如果你只使用 BPF 工具的话,就不必关注这些差异了。如果你经验丰富,是个开发者(像我一样),目前 bcc 的使用更难一些。
举一个 bcc 的 Python 前端的例子,下面是追踪硬盘 I/O 并打印出 I/O 大小的柱状图代码:
from bcc import BPF
from time import sleep
# load BPF program
b = BPF(text="""
#include <uapi/linux/ptrace.h>
#include <linux/blkdev.h>
BPF_HISTOGRAM(dist);
int kprobe__blk_account_io_completion(struct pt_regs *ctx, struct request *req)
{
dist.increment(bpf_log2l(req->__data_len / 1024));
return 0;
}
""")
# header
print("Tracing... Hit Ctrl-C to end.")
# trace until Ctrl-C
try:
sleep(99999999)
except KeyboardInterrupt:
print
# output
b["dist"].print_log2_hist("kbytes")
注意 Python 代码中嵌入的 C 语句(text=)。
这就完成了任务,但仍有改进的空间。好在我们有时间去做:人们使用 Linux 4.9 并能用上 BPF 还得好几个月呢,所以我们有时间来制造工具和前端。
高级语言
前端越简单,比如高级语言,所改进的可能就越不如你所期望的。绝大多数人使用封装好的工具(和图形界面),仅有少部分人能写出这些工具。但我不反对使用高级语言,比如 SystemTap,毕竟已经开发出来了。
#!/usr/bin/stap
/*
* opensnoop.stp Trace file open()s. Basic version of opensnoop.
*/
probe begin
{
printf("n%6s %6s %16s %sn", "UID", "PID", "COMM", "PATH");
}
probe syscall.open
{
printf("%6d %6d %16s %sn", uid(), pid(), execname(), filename);
}
如果拥有整合了语言和脚本的 SystemTap 前端与高性能的内置在内核中的 BPF 后端,会不会令人满意呢?RedHat 公司的 Richard Henderson 已经在进行相关工作了,并且发布了 初代版本!
这是 ply,一个完全新颖的 BPF 高级语言:
#!/usr/bin/env ply
kprobe:SyS_*
{
$syscalls[func].count()
}
这也是一份承诺。
尽管如此,我认为工具开发者的实际难题不是使用什么语言:而是要了解要用这些强大的工具做什么?
如何帮助我们
- 推广:BPF 追踪器目前还没有什么市场方面的进展。尽管有公司了解并在使用它(Facebook、Netflix、Github 和其它公司),但要广为人知尚需时日。你可以分享关于 BPF 的文章和资源给业内的其它公司来帮助我们。
- 教育:你可以撰写文章,发表演讲,甚至参与 bcc 文档的编写。分享 BPF 如何解决实际问题以及为公司带来收益的实例。
- 解决 bcc 的问题:参考 bcc issue list,这包含了错误和需要的特性。
- 提交错误:使用 bcc/BPF,提交你发现的错误。
- 创造工具:有很多可视化的工具需要开发,但请不要太草率,因为大家会先花几个小时学习使用你做的工具,所以请尽量把工具做的直观好用(参考我的文档)。就像 Mike Muuss 提及到他自己的 ping 程序:“要是我早知道这是我一生中最出名的成就,我就多开发一两天,添加更多选项。”
- 高级语言:如果现有的 bcc 前端语言让你很困扰,或许你能弄门更好的语言。要是你想将这门语言内建到 bcc 里面,你需要使用 libbcc。或者你可以帮助 SystemTap BPF 或 ply 的工作。
- 整合图形界面:除了 bcc 可以使用的 CLI 命令行工具,怎么让这些信息可视呢?延迟热点图,火焰图等等。
其它追踪器
那么 SystemTap、ktap、sysdig、LTTng 等追踪器怎么样呢?它们有个共同点,要么使用了 BPF,要么在自己的领域做得更好。会有单独的文章介绍它们自己。
至于 DTrace ?我们公司目前还在基于 FreeBSD 系统的 CDN 中使用它。
更多 bcc/BPF 的信息
我已经写了一篇《bcc/BPF 工具最终用户教程》,一篇《bcc Python 开发者教程》,一篇《bcc/BPF 参考手册》,并提供了一些有用的工具,每一个工具都有一个 example.txt 文件和 man page。我之前写过的关于 bcc 和 BPF 的文章有:
- eBPF: One Small Step (后来就叫做 BPF)
- bcc: Taming Linux 4.3+ Tracing Superpowers
- Linux eBPF Stack Trace Hack (现在官方支持追踪堆栈了)
- Linux eBPF Off-CPU Flame Graph
- Linux Wakeup and Off-Wake Profiling
- Linux Chain Graph Prototype
- Linux eBPF/bcc uprobes
- Linux BPF Superpowers
- Ubuntu Xenial bcc/BPF
- Linux bcc Tracing Security Capabilities
- Linux MySQL Slow Query Tracing with bcc/BPF
- Linux bcc ext4 Latency Tracing
- Linux bcc/BPF Run Queue (Scheduler) Latency
- Linux bcc/BPF Node.js USDT Tracing
- Linux bcc tcptop
- Linux 4.9's Efficient BPF-based Profiler
我在 Facebook 的 Performance@Scale Linux BPF Superpowers 大会上发表过一次演讲。十二月份,我将在 Boston 发表关于 BPF/bcc 在 USENIX LISA 方面的演讲和教程。
致谢
- Van Jacobson 和 Steve McCanne,他们创建了最初用作过滤器的 BPF 。
- Barton P. Miller,Jeffrey K. Hollingsworth,and Jon Cargille,发明了动态追踪,并发表论文《Dynamic Program Instrumentation for Scalable Performance Tools》,可扩展高性能计算协议 (SHPCC),于田纳西州诺克斯维尔市,1994 年 5 月发表。
- kerninst (ParaDyn, UW-Madison),展示了动态跟踪的价值的早期动态跟踪工具(上世纪 90 年代后期)
- Mathieu Desnoyers (在 LTTng),内核的主要开发者,主导 tracepoints 项目。
- IBM 开发的作为 DProbes 一部分的 kprobes,DProbes 在 2000 年时曾与 LTT 一起提供 Linux 动态追踪,但没有整合到一起。
- Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems),DTrace 的核心开发者,DTrace 是一款很棒的动态追踪工具,安全而且简单(2004 年)。对于动态追踪技术,DTrace 是科技的重要转折点:它很安全,默认安装在 Solaris 以及其它以可靠性著称的系统里。
- 来自 Sun Microsystems 的各部门的许多员工,促进了 DTrace,为我们带来了高级系统追踪的意识。
- Roland McGrath (在 Red Hat),utrace 项目的主要开发者,utrace 变成了后来的 uprobes。
- Alexei Starovoitov (PLUMgrid, 后来是 Facebook),加强版 BPF(可编程内核部件)的主要开发者。
- 那些帮助反馈、提交代码、测试以及针对增强版 BPF 补丁(请在 lkml 搜索 BPF)的 Linux 内核工程师: Wang Nan、 Daniel Borkmann、 David S. Miller、 Peter Zijlstra 以及其它很多人。
- Brenden Blanco (PLUMgrid),bcc 的主要开发者。
- Sasha Goldshtein (Sela) 开发了 bcc 中的跟踪点支持,和功能最强大的 bcc 工具 trace 及 argdist,帮助 USDT 项目的开发。
- Vicent Martí 和其它 Github 上的工程师,为 bcc 编写了基于 lua 的前端,帮助 USDT 部分项目的开发。
- Allan McAleavy、 Mark Drayton,和其他的改进 bcc 的贡献者。
感觉 Netflix 提供的环境和支持,让我能够编写 BPF 和 bcc 跟踪器并完成它们。我已经编写了多年的追踪工具(使用 TNF/prex、DTrace、SystemTap、ktap、ftrace、perf,现在是 bcc/BPF),并写书、博客以及评论,
最后,感谢 Deirdré 编辑了另外一篇文章。
总结
Linux 没有 DTrace(语言),但它现在有了,或者说拥有了 DTraceTookit(工具)。
通过增强内置的 BPF 引擎,Linux 4.9 内核拥有了用来支持现代化追踪的最后一项能力。内核支持这一最难的部分已经做完了。今后的任务包括更多的命令行执行工具,以及高级语言和图形用户界面。
对于性能分析产品的客户,这也是一件好事:你能查看延迟柱状图和热点图,CPU 处理和 CPU 之外的火焰图,拥有更好的时延断点和更低耗的工具。在用户空间按包跟踪和处理是没有效率的方式。
那么你什么时候会升级到 Linux 4.9 呢?一旦官方发布,新的性能测试工具就来了:apt-get install bcc-tools 。
开始享受它吧!
Brendan
via: http://www.brendangregg.com/blog/2016-10-27/dtrace-for-linux-2016.html
作者:Brendan Gregg 译者:GitFuture 校对:wxy
本文转载来自 Linux 中国: https://github.com/Linux-CN/archive
对这篇文章感觉如何?
You may also like






More in:Linux中国

捐赠 Let's Encrypt,共建安全的互联网

Let's Encrypt 正式发布,已经保护 380 万个域名

关于Linux防火墙iptables的面试问答

Lets Encrypt 已被所有主流浏览器所信任









