让我们做个简单的解释器(三)

早上醒来的时候,我就在想:“为什么我们学习一个新技能这么难?”
我不认为那是因为它很难。我认为原因可能在于我们花了太多的时间,而这件难事需要有丰富的阅历和足够的知识,然而我们要把这样的知识转换成技能所用的练习时间又不够。
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
要点在于:你认为自己有多了解那件事都无关紧要 —— 你得通过练习把知识变成技能。为了帮你练习,我把训练放在了这个系列的 第一部分 和 第二部分 了。当然,你会在今后的文章中看到更多练习,我保证 :)
好,让我们开始今天的学习。
到现在为止,你已经知道了怎样解释像 “7 + 3” 或者 “12 - 9” 这样的两个整数相加减的算术表达式。今天我要说的是怎么解析(识别)、解释有多个数字相加减的算术表达式,比如 “7 - 3 + 2 - 1”。
文中的这个算术表达式可以用下面的这个语法图表示:
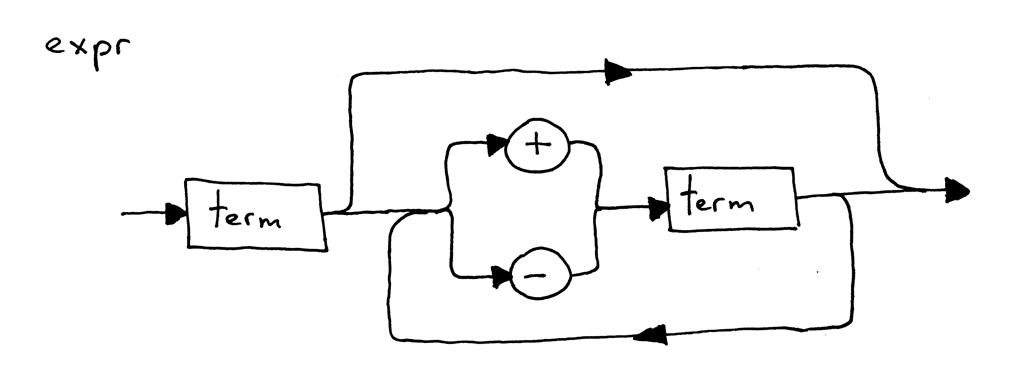
什么是 语法图 ? 语法图 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
语法图很容易读懂:按照箭头指向的路径。某些路径表示的是判断,有些表示的是循环。
你可以按照以下的方式读上面的语法图:一个 term 后面可以是加号或者减号,接着可以是另一个 term,这个 term 后面又可以是一个加号或者减号,后面又是一个 term,如此循环。从字面上你就能读懂这个图片了。或许你会奇怪,“term” 是什么、对于本文来说,“term” 就是个整数。
语法图有两个主要的作用:
- 它们用图形的方式表示一个编程语言的特性(语法)。
- 它们可以用来帮你写出解析器 —— 你可以根据下列简单规则把图片转换成代码。
你已经知道,识别出记号流中的词组的过程就叫做 解析。解释器或者编译器执行这个任务的部分叫做 解析器。解析也称为 语法分析,并且解析器这个名字很合适,你猜的对,就是 语法分析器。
根据上面的语法图,下面这些表达式都是合法的:
- 3
- 3 + 4
- 7 - 3 + 2 - 1
因为算术表达式的语法规则在不同的编程语言里面是很相近的,我们可以用 Python shell 来“测试”语法图。打开 Python shell,运行下面的代码:
>>> 3
3
>>> 3 + 4
7
>>> 7 - 3 + 2 - 1
5
意料之中。
表达式 “3 + ” 不是一个有效的数学表达式,根据语法图,加号后面必须要有个 term (整数),否则就是语法错误。然后,自己在 Python shell 里面运行:
>>> 3 +
File "<stdin>", line 1
3 +
^
SyntaxError: invalid syntax
能用 Python shell 来做这样的测试非常棒,让我们把上面的语法图转换成代码,用我们自己的解释器来测试,怎么样?
从之前的文章里(第一部分 和 第二部分)你知道 expr 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
以下代码片段显示了对应于图表的解析器代码。语法图里面的矩形方框(term)变成了 term 方法,用于解析整数,expr 方法和语法图的流程一致:
def term(self):
self.eat(INTEGER)
def expr(self):
# 把当前标记设为从输入中拿到的第一个标记
self.current_token = self.get_next_token()
self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
self.term()
elif token.type == MINUS:
self.eat(MINUS)
self.term()
你能看到 expr 首先调用了 term 方法。然后 expr 方法里面的 while 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 expr 方法,加入解释器的代码:
def term(self):
"""Return an INTEGER token value"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Parser / Interpreter """
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
因为解释器需要评估一个表达式, term 方法被改成返回一个整型值,expr 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
进行下一步,看看完整的解释器代码,好不?
这是新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
# 标记类型
#
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token 值: 非负整数值, '+', '-', 或无
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# 客户端字符输入, 例如. "3 + 5", "12 - 5",
self.text = text
# self.pos is an index into self.text
self.pos = 0
# 当前标记实例
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code #
##########################################################
def eat(self, token_type):
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
# 否则抛出一个异常
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value."""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter."""
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# 要在 Python3 下运行,请把 ‘raw_input’ 的调用换成 ‘input’
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
把上面的代码保存到 calc3.py 文件中,或者直接从 GitHub 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
这是我在自己的笔记本上运行的示例:
$ python calc3.py
calc> 3
3
calc> 7 - 4
3
calc> 10 + 5
15
calc> 7 - 3 + 2 - 1
5
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
5
calc> 3 +
Traceback (most recent call last):
File "calc3.py", line 147, in <module>
main()
File "calc3.py", line 142, in main
result = interpreter.expr()
File "calc3.py", line 123, in expr
result = result + self.term()
File "calc3.py", line 110, in term
self.eat(INTEGER)
File "calc3.py", line 105, in eat
self.error()
File "calc3.py", line 45, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
记得我在文章开始时提过的练习吗:它们在这儿,我保证过的:)
- 画出只包含乘法和除法的数学表达式的语法图,比如 “7 4 / 2 3”。认真点,拿只钢笔或铅笔,试着画一个。 修改计算器的源代码,解释只包含乘法和除法的数学表达式。比如 “7 4 / 2 3”。
- 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个词法分析器,读取输入并转换成标记流,一个解析器,从词法分析器提供的记号流中获取,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
检验你的理解:
- 什么是语法图?
- 什么是语法分析?
- 什么是语法分析器?
嘿,看!你看完了所有内容。感谢你们坚持到今天,而且没有忘记练习。:) 下次我会带着新的文章回来,尽请期待。
via: https://ruslanspivak.com/lsbasi-part3/
作者:Ruslan Spivak 译者:BriFuture 校对:wxy
本文转载来自 Linux 中国: https://github.com/Linux-CN/archive
对这篇文章感觉如何?
You may also like






More in:Linux中国

捐赠 Let's Encrypt,共建安全的互联网

Let's Encrypt 正式发布,已经保护 380 万个域名

关于Linux防火墙iptables的面试问答

Lets Encrypt 已被所有主流浏览器所信任









